note
[TOC]
OpenCV图像处理
OpenCV中文文档地址:https://www.cnblogs.com/Undo-self-blog/p/8423851.html
github上很不错的很多小demo:https://github.com/spmallick/learnopencv # 这个教程很不错。
从tensor转成numpy的数据,记得一定要转成 np.uint8 的数据格式才能展示出来哦
# ndarray转tensort
a_tensor = torch.from_numpy(input_img)
# tensor转回ndarray
torch_output = a_tensor.detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, (1, 2, 0)).astype((np.uint8))
一个错误:当安装的opencv版本太高时(4.5.4.60),显示图像时报错:“… qt.qpa.plugin: Could not load the Qt platform plugin “xcb” in “” even though it was found …”,然后解决办法是降低opencv的版本:pip install opencv-python==4.1.2.30
opencv源码中的sample中:==facedetect.py==带有人脸检测、眼睛检测,简单使用完全可以参考。
一、目标
1.掌握opencv基本应用
2.算子,算法
3.掌握轮廓边缘处理;角点处理;特征提取;跟踪
二、基本操作
2.1. 读取图片
import cv2
image = cv2.imread(r"1.png") #注意路径、图名中不能有中文名
#不给flags就是原格式,给0,就是灰度图
print(type(image)) #数据类型是numpy.ndarray
print(image.shape) #注意他的形状是(h,w,c),,跟 nunpy是一样的
cv2.imshow("123", image) #第一个参数是左上角显示的标签
cv2.waitKey(2000) #这代表2秒
# cv2.waitKey(0) #放0就是一直开着图片
注意:opencv读取的图片是BGR格式的,后面用PIL这些时要转换成RGB;
bgr = np.random.randn(2, 3, 64, 64)
rgb = bgr[:, ::-1, :, :]
_rgb = bgr[:, ::-1] #这俩是一样的,只是在通道上颠倒了
image_2 = image_2[:, :, ::-1].copy() # 或 img[..., ::-1]
#如果是这转了RGB后直接放到下面转tensor,一定要加个.copy(),不然会报错
data_2 = transforms.ToTensor()(image_2)
cv2.imshow(‘img’, image)注意:
有的时候对数据进行了一些操作,如白底黑字转成黑底白字,数据类型可能是int32,而cv2.imshow(),数据需要时uint8或float32,所以出错时,一定看看是不是数据类型错了。.dtype查看
提高对比度
在 第六点中第2小点拉普拉斯金字塔里、车牌提取有用到过。
img_new = cv2.convertScaleAbs(img_new, alpha=10, beta=0)
#为了更容易看清楚,做了个提高对比度的操作,就是黑的更黑,白的更白;一般就是操作alpha这个参数
2.2. 创建图片
image = np.empty((200, 100, 3), dtype = np.uint8)
image[..., 2] = 255 #注意OpenCV中图片通道是按照 BGR 来的;所以取0、1、2试试看
cv2.imwrite("2.jpg", image) #保存图片
image = image[:, :, ::-1] #这就可以将BGR转成RGB,进第一维,再进第二维,第三位通道全切反转
2.3. 色彩空间与转换
知识点:这个网页,一定去看。
- 色彩空间RGB/RGBA/RGAY/HSV/YUV
- 通道分离
- 理解HSV
RGB:它是一种==加法色彩空间==,其中颜色是通过红色、绿色和蓝色值的线性组合获得的。
-
==HSV==:
- HSV格式中,H (色彩/色度/色调(主要波长))的取值范围是[0, 180], S (饱和度)的取值范围[0, 255], V (亮度/强度)的取值范围[0, 255]。 #这只是再opencv中(不是很确定)
- 但是不同的软件使用的值可能不同。所以当你需要拿OpenCV的HSV值与其他软件的HSV值进行对比时,一定要记得归一化。
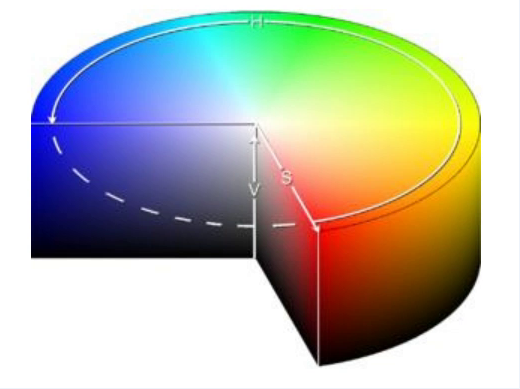
-
==Lab==: cv2.COLOR_BGR2LAB # 不值为啥不是 2Lab opencv中大小写都有
- Lab的颜色格式中:
- L:亮度(强度); # 这个通道与颜色信息无关,只对亮度进行编码
- a:颜色成分从Green到Magenta(洋红);
- b:颜色成分从Blue到Yellow。
- 感知上均匀的颜色空间,近似于我们感知颜色的方式;独立于设备(捕获或显示);在 Adobe Photoshop 中广泛使用;通过复杂的变换方程与RGB颜色空间相关。
- Lab的颜色格式中:
-
==YCrCb==: # 亮度 (Y) 和色度 (Cr, Cb) 分量
- YCrCb 颜色空间源自RGB颜色空间:
- Y:伽马校正后从RGB中获得的亮度或亮度分量;
- Cr:R – Y ( how far is the red component from Luma );
- Cb:B – Y ( how far is the blue component from Luma )。
- 属性:将亮度和色度分量分离到不同的通道中;主要用于电视传输的压缩(Cr和Cb分量)。
- YCrCb 颜色空间源自RGB颜色空间:
==获取BGR、HSV值==
这是learnopencv里的项目,可以获取某张图任意位置对应的BGR、HSV、Lab、YCrCb的值,然后就可以拿到这些值进行分割了: 以下使用的图片在./images/rubs里面。然后对应的c++版本在c++那里面。
-
interactiveColorDetect.py: # 获取颜色具体值
import cv2,argparse,glob import numpy as np # mouse callback function def showPixelValue(event,x,y,flags,param): global img, combinedResult, placeholder if event == cv2.EVENT_MOUSEMOVE: # get the value of pixel from the location of mouse in (x,y) bgr = img[y,x] # Convert the BGR pixel into other colro formats ycb = cv2.cvtColor(np.uint8([[bgr]]),cv2.COLOR_BGR2YCrCb)[0][0] lab = cv2.cvtColor(np.uint8([[bgr]]),cv2.COLOR_BGR2Lab)[0][0] hsv = cv2.cvtColor(np.uint8([[bgr]]),cv2.COLOR_BGR2HSV)[0][0] # Create an empty placeholder for displaying the values placeholder = np.zeros((img.shape[0],400,3),dtype=np.uint8) # fill the placeholder with the values of color spaces cv2.putText(placeholder, "BGR {}".format(bgr), (20, 70), cv2.FONT_HERSHEY_COMPLEX, .9, (255,255,255), 1, cv2.LINE_AA) cv2.putText(placeholder, "HSV {}".format(hsv), (20, 140), cv2.FONT_HERSHEY_COMPLEX, .9, (255,255,255), 1, cv2.LINE_AA) cv2.putText(placeholder, "YCrCb {}".format(ycb), (20, 210), cv2.FONT_HERSHEY_COMPLEX, .9, (255,255,255), 1, cv2.LINE_AA) cv2.putText(placeholder, "LAB {}".format(lab), (20, 280), cv2.FONT_HERSHEY_COMPLEX, .9, (255,255,255), 1, cv2.LINE_AA) # Combine the two results to show side by side in a single image combinedResult = np.hstack([img,placeholder]) cv2.imshow('PRESS P for Previous, N for Next Image',combinedResult) if __name__ == '__main__' : # load the image and setup the mouse callback function global img files = glob.glob('images/rubs/rub*.jpg') files.sort() img = cv2.imread(files[0]) img = cv2.resize(img,(400,400)) cv2.imshow('PRESS P for Previous, N for Next Image',img) # Create an empty window cv2.namedWindow('PRESS P for Previous, N for Next Image') # Create a callback function for any event on the mouse cv2.setMouseCallback('PRESS P for Previous, N for Next Image',showPixelValue) i = 0 while True: k = cv2.waitKey(1) & 0xFF # check next image in the folder if k == ord('n'): i += 1 img = cv2.imread(files[i%len(files)]) img = cv2.resize(img,(400,400)) cv2.imshow('PRESS P for Previous, N for Next Image',img) # check previous image in folder elif k == ord('p'): i -= 1 img = cv2.imread(files[i%len(files)]) img = cv2.resize(img,(400,400)) cv2.imshow('PRESS P for Previous, N for Next Image',img) elif k == 27: cv2.destroyAllWindows() break -
interactiveColorSegment.py # 根据上面获取到的值来调整滑动条来进行分割
import cv2,time,argparse,glob import numpy as np #global variable to keep track of show = False def onTrackbarActivity(x): global show show = True pass if __name__ == '__main__' : # Get the filename from the command line files = glob.glob('images/rubs/rub*.jpg') files.sort() # load the image original = cv2.imread(files[0]) #Resize the image rsize = 250 original = cv2.resize(original,(rsize,rsize)) #position on the screen where the windows start initialX = 50 initialY = 50 #creating windows to display images cv2.namedWindow('P-> Previous, N-> Next',cv2.WINDOW_AUTOSIZE) cv2.namedWindow('SelectBGR',cv2.WINDOW_AUTOSIZE) cv2.namedWindow('SelectHSV',cv2.WINDOW_AUTOSIZE) cv2.namedWindow('SelectYCB',cv2.WINDOW_AUTOSIZE) cv2.namedWindow('SelectLAB',cv2.WINDOW_AUTOSIZE) #moving the windows to stack them horizontally cv2.moveWindow('P-> Previous, N-> Next',initialX,initialY) cv2.moveWindow('SelectBGR',initialX + (rsize + 5),initialY) cv2.moveWindow('SelectHSV',initialX + 2*(rsize + 5),initialY) cv2.moveWindow('SelectYCB',initialX + 3*(rsize + 5),initialY) cv2.moveWindow('SelectLAB',initialX + 4*(rsize + 5),initialY) #creating trackbars to get values for YCrCb cv2.createTrackbar('YMin','SelectYCB',0,255,onTrackbarActivity) cv2.createTrackbar('YMax','SelectYCB',0,255,onTrackbarActivity) cv2.createTrackbar('CrMin','SelectYCB',0,255,onTrackbarActivity) cv2.createTrackbar('CrMax','SelectYCB',0,255,onTrackbarActivity) cv2.createTrackbar('CbMin','SelectYCB',0,255,onTrackbarActivity) cv2.createTrackbar('CbMax','SelectYCB',0,255,onTrackbarActivity) #creating trackbars to get values for HSV cv2.createTrackbar('HMin','SelectHSV',0,180,onTrackbarActivity) cv2.createTrackbar('HMax','SelectHSV',0,180,onTrackbarActivity) cv2.createTrackbar('SMin','SelectHSV',0,255,onTrackbarActivity) cv2.createTrackbar('SMax','SelectHSV',0,255,onTrackbarActivity) cv2.createTrackbar('VMin','SelectHSV',0,255,onTrackbarActivity) cv2.createTrackbar('VMax','SelectHSV',0,255,onTrackbarActivity) #creating trackbars to get values for BGR cv2.createTrackbar('BGRBMin','SelectBGR',0,255,onTrackbarActivity) cv2.createTrackbar('BGRBMax','SelectBGR',0,255,onTrackbarActivity) cv2.createTrackbar('BGRGMin','SelectBGR',0,255,onTrackbarActivity) cv2.createTrackbar('BGRGMax','SelectBGR',0,255,onTrackbarActivity) cv2.createTrackbar('BGRRMin','SelectBGR',0,255,onTrackbarActivity) cv2.createTrackbar('BGRRMax','SelectBGR',0,255,onTrackbarActivity) #creating trackbars to get values for LAB cv2.createTrackbar('LABLMin','SelectLAB',0,255,onTrackbarActivity) cv2.createTrackbar('LABLMax','SelectLAB',0,255,onTrackbarActivity) cv2.createTrackbar('LABAMin','SelectLAB',0,255,onTrackbarActivity) cv2.createTrackbar('LABAMax','SelectLAB',0,255,onTrackbarActivity) cv2.createTrackbar('LABBMin','SelectLAB',0,255,onTrackbarActivity) cv2.createTrackbar('LABBMax','SelectLAB',0,255,onTrackbarActivity) # show all images initially cv2.imshow('SelectHSV',original) cv2.imshow('SelectYCB',original) cv2.imshow('SelectLAB',original) cv2.imshow('SelectBGR',original) i = 0 while True: cv2.imshow('P-> Previous, N-> Next',original) k = cv2.waitKey(1) & 0xFF # check next image in folder if k == ord('n'): i += 1 original = cv2.imread(files[i%len(files)]) original = cv2.resize(original,(rsize,rsize)) show = True # check previous image in folder elif k == ord('p'): i -= 1 original = cv2.imread(files[i%len(files)]) original = cv2.resize(original,(rsize,rsize)) show = True # Close all windows when 'esc' key is pressed elif k == 27: break if show: # If there is any event on the trackbar show = False # Get values from the BGR trackbar BMin = cv2.getTrackbarPos('BGRBMin','SelectBGR') GMin = cv2.getTrackbarPos('BGRGMin','SelectBGR') RMin = cv2.getTrackbarPos('BGRRMin','SelectBGR') BMax = cv2.getTrackbarPos('BGRBMax','SelectBGR') GMax = cv2.getTrackbarPos('BGRGMax','SelectBGR') RMax = cv2.getTrackbarPos('BGRRMax','SelectBGR') minBGR = np.array([BMin, GMin, RMin]) maxBGR = np.array([BMax, GMax, RMax]) # Get values from the HSV trackbar HMin = cv2.getTrackbarPos('HMin','SelectHSV') SMin = cv2.getTrackbarPos('SMin','SelectHSV') VMin = cv2.getTrackbarPos('VMin','SelectHSV') HMax = cv2.getTrackbarPos('HMax','SelectHSV') SMax = cv2.getTrackbarPos('SMax','SelectHSV') VMax = cv2.getTrackbarPos('VMax','SelectHSV') minHSV = np.array([HMin, SMin, VMin]) maxHSV = np.array([HMax, SMax, VMax]) # Get values from the LAB trackbar LMin = cv2.getTrackbarPos('LABLMin','SelectLAB') AMin = cv2.getTrackbarPos('LABAMin','SelectLAB') BMin = cv2.getTrackbarPos('LABBMin','SelectLAB') LMax = cv2.getTrackbarPos('LABLMax','SelectLAB') AMax = cv2.getTrackbarPos('LABAMax','SelectLAB') BMax = cv2.getTrackbarPos('LABBMax','SelectLAB') minLAB = np.array([LMin, AMin, BMin]) maxLAB = np.array([LMax, AMax, BMax]) # Get values from the YCrCb trackbar YMin = cv2.getTrackbarPos('YMin','SelectYCB') CrMin = cv2.getTrackbarPos('CrMin','SelectYCB') CbMin = cv2.getTrackbarPos('CbMin','SelectYCB') YMax = cv2.getTrackbarPos('YMax','SelectYCB') CrMax = cv2.getTrackbarPos('CrMax','SelectYCB') CbMax = cv2.getTrackbarPos('CbMax','SelectYCB') minYCB = np.array([YMin, CrMin, CbMin]) maxYCB = np.array([YMax, CrMax, CbMax]) # Convert the BGR image to other color spaces imageBGR = np.copy(original) imageHSV = cv2.cvtColor(original,cv2.COLOR_BGR2HSV) imageYCB = cv2.cvtColor(original,cv2.COLOR_BGR2YCrCb) imageLAB = cv2.cvtColor(original,cv2.COLOR_BGR2LAB) # Create the mask using the min and max values obtained from trackbar and apply bitwise and operation to get the results maskBGR = cv2.inRange(imageBGR,minBGR,maxBGR) resultBGR = cv2.bitwise_and(original, original, mask = maskBGR) maskHSV = cv2.inRange(imageHSV,minHSV,maxHSV) resultHSV = cv2.bitwise_and(original, original, mask = maskHSV) maskYCB = cv2.inRange(imageYCB,minYCB,maxYCB) resultYCB = cv2.bitwise_and(original, original, mask = maskYCB) maskLAB = cv2.inRange(imageLAB,minLAB,maxLAB) resultLAB = cv2.bitwise_and(original, original, mask = maskLAB) # Show the results cv2.imshow('SelectBGR',resultBGR) cv2.imshow('SelectYCB',resultYCB) cv2.imshow('SelectLAB',resultLAB) cv2.imshow('SelectHSV',resultHSV) cv2.destroyAllWindows()
这接下来的是对颜色的一个分析,酌情看吧(图片在./images/pieces):dataAnalysis.py
#import the required packages
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
import cv2,glob
import numpy as np
#specify the color for which histogram is to be plotted
color = './images/pieces/yellow'
# whether the plot should be on full scale or zoomed
zoom = 1
# load all the files in the folder
files = glob.glob(color + '*.jpg')
files.sort()
# empty arrays for separating the channels for plotting
B = np.array([])
G = np.array([])
R = np.array([])
H = np.array([])
S = np.array([])
V = np.array([])
Y = np.array([])
Cr = np.array([])
Cb = np.array([])
LL = np.array([])
LA = np.array([])
LB = np.array([])
# Data creation
# append the values from each file to the respective channel
for fi in files[:]:
# BGR
im = cv2.imread(fi)
b = im[:,:,0]
b = b.reshape(b.shape[0]*b.shape[1])
g = im[:,:,1]
g = g.reshape(g.shape[0]*g.shape[1])
r = im[:,:,2]
r = r.reshape(r.shape[0]*r.shape[1])
B = np.append(B,b)
G = np.append(G,g)
R = np.append(R,r)
# HSV
hsv = cv2.cvtColor(im,cv2.COLOR_BGR2HSV)
h = hsv[:,:,0]
h = h.reshape(h.shape[0]*h.shape[1])
s = hsv[:,:,1]
s = s.reshape(s.shape[0]*s.shape[1])
v = hsv[:,:,2]
v = v.reshape(v.shape[0]*v.shape[1])
H = np.append(H,h)
S = np.append(S,s)
V = np.append(V,v)
# YCrCb
ycb = cv2.cvtColor(im,cv2.COLOR_BGR2YCrCb)
y = ycb[:,:,0]
y = y.reshape(y.shape[0]*y.shape[1])
cr = ycb[:,:,1]
cr = cr.reshape(cr.shape[0]*cr.shape[1])
cb = ycb[:,:,2]
cb = cb.reshape(cb.shape[0]*cb.shape[1])
Y = np.append(Y,y)
Cr = np.append(Cr,cr)
Cb = np.append(Cb,cb)
# Lab
lab = cv2.cvtColor(im,cv2.COLOR_BGR2LAB)
ll = lab[:,:,0]
ll = ll.reshape(ll.shape[0]*ll.shape[1])
la = lab[:,:,1]
la = la.reshape(la.shape[0]*la.shape[1])
lb = lab[:,:,2]
lb = lb.reshape(lb.shape[0]*lb.shape[1])
LL = np.append(LL,ll)
LA = np.append(LA,la)
LB = np.append(LB,lb)
# Plotting the histogram
nbins = 10
plt.figure(figsize=[20,10])
plt.subplot(2,3,1)
plt.hist2d(B, G, bins=nbins, norm=LogNorm())
plt.xlabel('B')
plt.ylabel('G')
plt.title('RGB')
if not zoom:
plt.xlim([0,255])
plt.ylim([0,255])
plt.colorbar()
plt.subplot(2,3,2)
plt.hist2d(B, R, bins=nbins, norm=LogNorm())
plt.colorbar()
plt.xlabel('B')
plt.ylabel('R')
plt.title('RGB')
if not zoom:
plt.xlim([0,255])
plt.ylim([0,255])
plt.subplot(2,3,3)
plt.hist2d(R, G, bins=nbins, norm=LogNorm())
plt.colorbar()
plt.xlabel('R')
plt.ylabel('G')
plt.title('RGB')
if not zoom:
plt.xlim([0,255])
plt.ylim([0,255])
plt.subplot(2,3,4)
plt.hist2d(H, S, bins=nbins, norm=LogNorm())
plt.colorbar()
plt.xlabel('H')
plt.ylabel('S')
plt.title('HSV')
if not zoom:
plt.xlim([0,180])
plt.ylim([0,255])
plt.subplot(2,3,5)
plt.hist2d(Cr, Cb, bins=nbins, norm=LogNorm())
plt.colorbar()
plt.xlabel('Cr')
plt.ylabel('Cb')
plt.title('YCrCb')
if not zoom:
plt.xlim([0,255])
plt.ylim([0,255])
plt.subplot(2,3,6)
plt.hist2d(LA, LB, bins=nbins, norm=LogNorm())
plt.colorbar()
plt.xlabel('A')
plt.ylabel('B')
plt.title('LAB')
if not zoom:
plt.xlim([0,255])
plt.ylim([0,255])
plt.savefig(color + '.png',bbox_inches='tight')
else:
plt.savefig(color + '-zoom.png',bbox_inches='tight')
plt.show()
例如:提取图中的文字|范围
用的HSV色彩空间
image = cv2.imread("3.jpg")
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # 转成HSV的
# 要提取范围的上下限
blue_min = np.array([100, 200, 100]) # 三个通道在hsv中的最小值
blue_max = np.array([200, 255, 200]) # 三个通道在hsv中的最大值
mask = cv2.inRange(hsv, blue_min, blue_max) # 生成掩码
result = cv2.bitwise_and(image, image, mask=mask) # 把3掩码跟原图加起来
cv2.imshow("frame", image)
cv2.imshow("mask", mask)
cv2.imshow("result", result)
cv2.imshow("hsv", hsv)
cv2.waitKey(0)
现在明白范围了,如提取防防松动标记,代码就可以这么写:(和循环的结果是一样的)
import cv2
import numpy as np
image = cv2.imread("./images/04.jpg") # 螺丝上有红色的一条线的图
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) #转成HSV的
lower_red = np.array([156, 41, 46]) # 给的hsv中红色的值的范围(下限)
upper_red = np.array([180, 255, 255]) # (上限)
mask = cv2.inRange(hsv, lower_red, upper_red) # 生成掩码
result = cv2.bitwise_and(image, image, mask = mask) # 把3掩码跟原图加起来
cv2.imshow("frame", image)
cv2.imshow("mask", mask)
cv2.imshow("result", result)
cv2.imshow("hsv", hsv)
cv2.waitKey(0)
2.4. 图像灰度与二值化
知识点:
- 把图像变成0,1两个数字表示;
- 把图像灰度化是把图像变为黑(0) 、灰(1-254)、白(255) 。如果是RGB或GBRA多通道,每个像素点的三个通道颜色值相同;
- 二值化和灰度化图像常用于图像预处理。
二值化转换方法:
image = cv2.imread("1.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #转灰度图
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) #转二值图,就0和255;最后一个参数表示从图片的灰度信息中自动获取最佳阈值; 这里因为生成了有两个元素的元组,我们需要的是第二个,所以,ret其实没用的
cv2.imshow("gray", gray)
cv2.imshow("binary", binary)
cv2.waitKey(0)
2.5. 阈值操作
#就是范围内大于某个值的都设定为一个值,小于那某个值的又设定为另一个值 阈值操作前都要先灰度化
简单阈值、自适应阈值、二值化操作
2.5.1 简单阈值
img = cv2.imread('5.jpg',0)
ret,thresh1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) #像素小于阈值127的设为0,大于127的设为255
ret,thresh2 = cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV) #_INV是求逆;跟上面相反
ret,thresh3 = cv2.threshold(img,127,255,cv2.THRESH_TRUNC)
ret,thresh4 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO)
ret,thresh5 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
2.5.2 自适应阈值
前面的部分我们使用是全局阈值,整幅图像采用同一个数作为阈值。当时这种方法并不适应与所有情况,尤其是当同一幅图像上的不同部分的具有不同亮度时。这种情况下我们需要采用自适应阈值。此时的阈值是根据图像上的每一个小区域计算与其对应的阈值。因此在同- -幅图像上的不同区域采用的是不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果。
这种方法需要我们指定三个参数,返回值只有一个。
-
AdaptiveMethod:指定计算阈值的方法,常用这两个
-
CV2.ADPTIVE_THRESH_MEAN_C # 阈值取自相邻区 域的平均值
类似于卷积,临近区域取平均值做为阈值,以它为判断 -
CV2.ADPTIVE_THRESH_GAUSSIAN_C # 阈值取值相邻区域的加权和,权重为一一个高斯窗口 给临近区域每个值一个类似高斯分布的权,越靠中间权重越大;高斯核 这个效果最好
-
-
BlockSize:邻域大小(用来计算阈值的区域大小)。
-
C: 这就是是一一个常数,阈值就等于的平均值或者加权平均值减去这个常数
一般置为0,就是在计算后得不到我想要的阈值,就通过一个常数来改变
"""高斯核"""
image_2 = cv2.imread("1.jpg")
image_2_gray = cv2.cvtColor(image_2, cv2.COLOR_BGR2GRAY)
bw_image = cv2.adaptiveThreshold(image_2_gray, 255,\
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 15, 5)
#255是设定的最大阈值;15代表核的大小(一般3,5,7,9);5代表计算阈值过程中需要减去的常量
cv2.imshow("1", bw_image)
cv2.waitKey(0)
2.5. 图像上的运算(加水印)
学习图像上的算术运算符,加法,减法,图像混合等 #加水印
2.5.1 图像加减
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x,y)) #值必须在0~255,超过255会被规划到这个范围内
print(cv2.subtract(x,y)) #subtract:减法
2.5.2 图像混合
这其实也是加法,但是不同的是两幅图的权重不同。
img1 = cv2.imread('1.jpg')
img2 = cv2.imread('9.jpg')
dst = cv2.addWeighted(img1, 0.7, img2, 0.3, 0)
#小数是两幅图各自的权重,最后一个数字是在最后的图片上一个值,这个值越大,越白;0就是原样
# dst = cv2.add(img1,img2) #加法试一试
cv2.imshow('dst', dst)
cv2.waitKey(0)
2.5.3 按位运算
这个加水印,还不用两张图保持一样大
这里包括的按位操作有: AND, OR,NOT, XOR等。当我们提取图像的一部分,选择非矩形ROI时这些操作会很有用(下- -章你就会明白)。下面的例子就是教给我们如何改变一 幅图的特定区域。我想把OpenCV的标志放到另一幅图像上。如果我使用加法,颜色会改变,如果使用混合,会得到透明效果,但是我不想要透明 #这几个去试试,
"""这里不太懂。。视频第三个30分钟左右"""
img1 = cv2.imread('1.jpg')
img2 = cv2.imread('9.jpg')
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
#这时候的mask是黑底白字; (mask一般都是黑底,然后里面的图像是白的)
mask_inv = cv2.bitwise_not(mask) #1 not这就是转成了白底黑字
# cv2.imshow("mask_inv",mask_inv)
img1_bg = cv2.bitwise_and(img1, img1, mask=mask_inv) #1 这时的水印是黑字
# cv2.imshow("img1_bg",img1_bg)
img2_fg = cv2.bitwise_and(img2, img2, mask=mask) #2 这时候是黑底白字,但是跟图片原来已经不一样了
# cv2.imshow("img2_fg",img2_fg)
dst = cv2.add(img1_bg, img2_fg) #2 这时候水印是白字
cv2.imshow('res', dst)
cv2.waitKey(0)
##这视频里在这有一个题,做水印,在第三个视频的30多分钟,记得去做啊
总结:先将有字的图灰度化,再二值化的结果取第二个值,后面也不清楚了啊!!
2.6. 出现函数总结
梗概放在这,具体要求要看每个参数的意义,翻上去找!
"""按位相加,生成水印,提取文字"""
result = cv2.bitwise_and(image, image, mask = mask)
"""二值化"""
result = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
"""自适应高斯二值化"""
result = cv2.adaptiveThreshold(image_2_gray, 255,\
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 15, 5)
"""带权重的图像混合"""
result = cv2.addWeighted(img1, 0.7, img2, 0.3, 0)
三、图形绘制及几何变换
3.1. 基本图形绘制(重要)
注意一点:应该因为c++的问题,在这些函数执行时,是可以不要返回值的,即:
image = cv2.imread(r"C:\Users\Administrator\Desktop\label_pic\5.jpg")
cv2.rectangle(image, [50, 50], [300, 300], (0, 255, 255), 3)
cv2.imshow("11", image) # 此时image就已经被改变了
cv2.waitKey(0)
哪怕给了返回值,即 img = cv2.rectangle(image, [50, 50], [300, 300], (0, 255, 255), 3),那得到的结果,img跟image也是一模一样的。所以要保留原图,一定要提前复制:
-
python:
image = cv2.imread(r"5.jpg") img = image.copy() -
c++:
cv::Mat debugImage; cv::Mat image = cv::imread("5.jpg"); image.copyTo(debugImage);
3.1.1 直线|圆|矩形|椭圆
注:坐标点的值只可以括号元祖的形式给,也可以是列表,但值一样要是int整数,有时候算出来的是numpy数组,看起来也是int整型,但打印其类型是“numpy.int32”,就用int()把这个值再转换一下。
image = cv2.imread("1.png")
cv2.line(image, (100, 30), (210, 180), color = (0, 0, 255), thickness = 2)
cv2.circle(image, (50, 50), radius = 30, color = (0, 0, 255), thickness = 2)
cv2.rectangle(image, (400,400), (600, 700), color = (0,0,225), thickness = 2) #2就代表2个像素宽
cv2.ellipse(image, (800, 800), (100, 50), 0, 0, 360, (255, 0, 0), thickness= -1) #-1就是填充了
cv2.imshow("girl", image)
cv2.waitKey(0)
3.1.2 多边形
这里一定要isClosed=True这个参数
image = cv2.imread("1.png")
#定义四个坐标点
pts = np.array([[10, 5], [50, 10], [70, 20], [20, 30]], dtype = np.int32)
# 还可以考虑用 cv2.drawContours(img, [pts], 0, (0, 0, 255), -1) # -1是把区域填充
cv2.polylines(image, [pts], isClosed=True, color=(0, 0, 255), thickness=2) # 注意pts要用中括号括起来,有时候一个二维数组也需要:[np.asarray(pts, np.int32)],(或者直接用np.intp(pts)) pts是一个二维数组。
cv2.imshow("pic show", image)
cv2.waitKey(0)
3.1.3 写文字
image = cv2.imread("1.jpg")
# font = cv2.FONT_HERSHEY_SIMPLEX # 给字体,可以试下其他的
font = cv2.FONT_HERSHEY_PLAIN # 和这个字体,结合cv2.LINE_AA还挺好看的
cv2.putText(image, "beautiful", (10, 30), font, 2, (0, 0, 225), 2, lineType= cv2.LINE_AA) # 最后一个是线型
cv2.imshow("...", image)
cv2.waitKey(0)
3.1.4 resize
image = cv2.imread("1.jpg")
rows, clos, channel = image.shape
# 第二个参数给的是 (w, h); 它本来的形状的是(h, w, c)
dst = cv2.resize(image, (clos * 2, rows * 2), interpolation= cv2.INTER_CUBIC) #这个参数是立方插值的意思;神经网络上采样的时候会用
"""
最后一个参数是插值方式;
1.临近插值,图片变大,像素值增多,临近是什么就增加什么,如原始是[1 2 3 4].reshape(2,2),
扩大两倍就给它变成11223344,大概意思
2.线性插值,水平上就取相邻俩数的均值,竖直上就取上下俩数的均值;
3.双线插值,取周围的值作为参考
"""
cv2.imshow("image", image)
cv2.imshow("dst", dst)
cv2.waitKey(0)
3.1.5 transpose #就很简单的长宽交换
image = cv2.imread("1.png")
dst = cv2.transpose(image)
cv2.imshow("dst", dst)
cv2.waitKey(0)
3.1.6. flip 镜像或颠倒
image = cv2.imread("1.png")
dst = cv2.flip(image, 1)
#-1:上下颠倒且左右镜像;; 0:上下颠倒;; 1:左右镜像
cv2.imshow("dst", dst)
cv2.waitKey(0)
3.1.7 fillPoly填充
填充还可以用画轮廓的 cv2.drawContours 实现,线宽给-1那种。
import cv2
import numpy as np
image = np.zeros((height, width, 3), dtype = np.uint8)
points = np.array([[60, 60], [40, 10], [100, 100], [200, 60], [300, 50]], dtype=np.int) # 注意这里只能用 int32及以上,用int8、int16这种都会报错
cv2.fillPoly(image, [points], (0, 255, 255))
3.2. 几何变换
3.2.1. 仿射变换
注解:任意一个二维图像,我们乘以一个仿射矩阵,就能得到仿射变换后的图像。变换包含:缩放、旋转、平移、倾斜、镜像。
这一般都要构件仿射矩阵,比较麻烦,真的要用时,去看这个二次封装的包imutils
记住:这变换矩阵是在矩阵乘法的左边,要变换的坐标在右边且x、y是列。例子在这里
仿射矩阵:
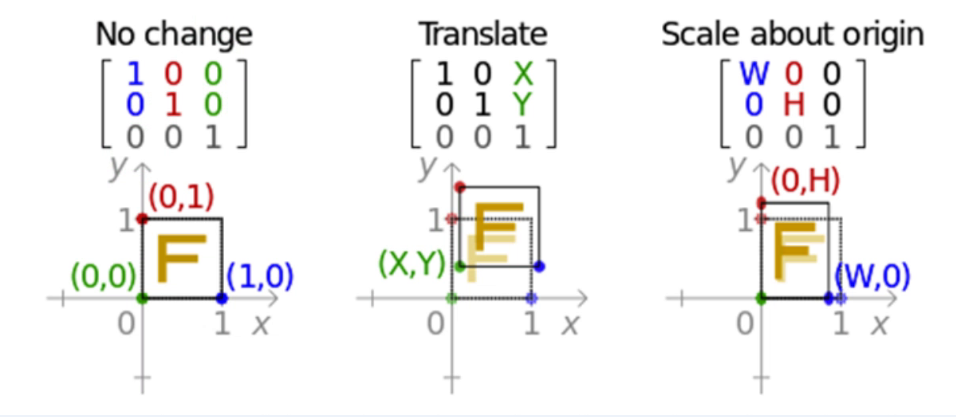
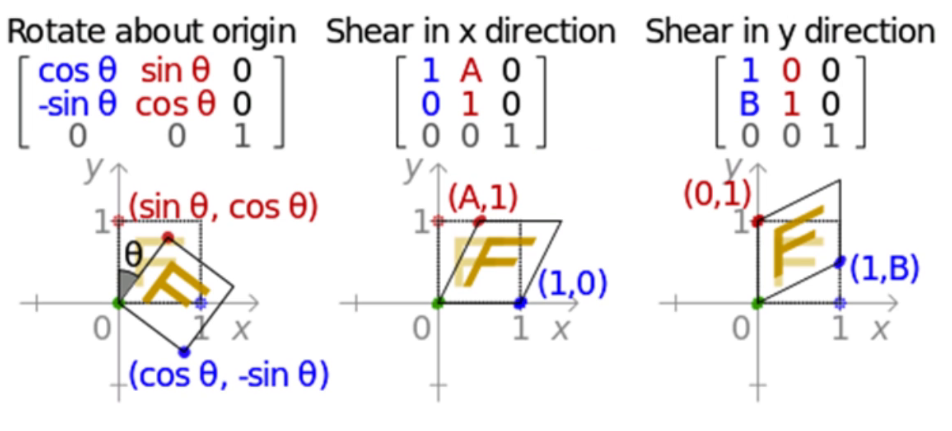
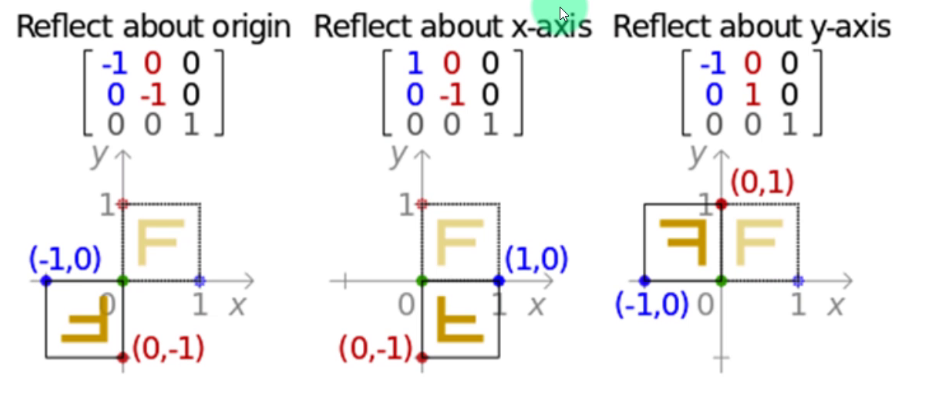
下面最后一行[0,0,1]是一个自由度,让其去构建的;若要有多个变换的时候,依次去乘相对应的仿射矩阵,也可以后面多个仿射矩阵先相乘后变成一个矩阵,但注意顺序不能变,矩阵是没有交换律的。
3.2.2. 透视变换
我的理解是将图片从四个角拉大,于是就拉薄了,然后就清晰一些,也有摆正的味道

import cv2
import numpy as np
img = cv2.imread("4.jpg")
pts1 = np.float32([[25, 30], [179, 25], [12, 188], [189, 190]]) # 这张图四个角点坐标是在画图工具中大致获取来的
pts2 = np.float32([[0, 0], [200, 0], [0, 200], [200, 200]]) # 这四个坐标是自己设置想拉成的样子,一般是拉得更大,注意必须是浮点型啊
M = cv2.getPerspectiveTransform(pts1, pts2) # 创建透视矩阵
dst = cv2.warpPerspective(img, M, (200, 201)) # 接下来这跟仿射矩阵差不多
cv2.imshow("src", img)
cv2.imshow("dst", dst)
cv2.waitKey(0)
-
以下是从一本书的例子来的:==机读卡识别==

import cv2 import numpy as np A = (60, 90) # A选项横坐标范围 B = (130, 160) # B选项横坐标范围 C = (200, 230) # C选项横坐标范围 D = (270, 300) # D选项横坐标范围 # 每一道题的纵坐标范围 questions_ordinate = [[15, 30], [60, 75], [105, 120], [145, 160], [195, 210], [280, 295], [324, 335], [365, 380], [410, 425], [455, 465]] result = {} # 定义一个空字典,用于保存机读卡上填涂的答案 # 获取矩形图案的平面透视图 def perspective(img): w, h = 320, 480 # 俯视图的宽高 tmp = cv2.GaussianBlur(img, (5, 5), 0) # 高斯滤波 tmp = cv2.Canny(tmp, 50, 120) # 变为二值边缘图像 tmp = cv2.morphologyEx(tmp, cv2.MORPH_CLOSE, (15, 15), iterations=2) # 闭运算,保证边缘闭合 res = cv2.resize(tmp, None, fx=0.35, fy=0.35) # 缩放执行闭运算后的图像 cv2.imshow("1", res) # 窗口显示缩放后的、机读卡的边缘信息图像 contours, _ = cv2.findContours(tmp, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 检测轮廓 for contour in contours: # 遍历所有轮廓 area = cv2.contourArea(contour) # 计算轮廓面积 if area > 10000: # 只处理面积廓大于10000的轮廓 length = cv2.arcLength(contour, True) # 获取轮廓周长 # 计算出轮廓的端点(用的是轮廓近似的API) approx = cv2.approxPolyDP(contour, 0.1 * length, True) pts1 = np.float32(approx) # 轮廓四个端点的坐标 pts2 = np.float32([[0, 0], [0, h], [w, h], [w, 0]]) # 平面透视图对应的四个端点坐标 M = cv2.getPerspectiveTransform(pts1, pts2) # 创建透视图M矩阵 tmp = cv2.warpPerspective(img, M, (w, h)) # 根据M矩阵做透视变换 return tmp # 根据横坐标判断选项 def get_result(x): if A[0] <= x <= A[1]: return "A" if B[0] <= x <= B[1]: return "B" if C[0] <= x <= C[1]: return "C" if D[0] <= x <= D[1]: return "D" # 根据纵坐标判断题号 def get_question(y): for i in range(0, len(questions_ordinate)): # 遍历10道题的纵坐标的取值范围 y_bottom, y_up = questions_ordinate[i] # 获取每一个题目的纵坐标范围 if y_bottom <= y <= y_up: # 如果在该题目坐标范围内 return i + 1 # 返回题号 img = cv2.imread("answer.jpg") # 机读答题卡的照片 tmp = perspective(img) # 获取答题卡正面透视图 cv2.imshow("2", tmp) # 窗口显示机读卡的平面透视图 tmp = cv2.cvtColor(tmp, cv2.COLOR_BGR2GRAY) # 转为灰度图 _, tmp = cv2.threshold(tmp, 150, 255, cv2.THRESH_BINARY) # 二值化阈值处理 cv2.imshow("3", tmp) # 窗口显示对平面透视图进行二值化阈值处理的结果 k = np.ones((3, 3), np.uint8) # 形态学操作所用的核 tmp = cv2.morphologyEx(tmp, cv2.MORPH_CLOSE, k, iterations=2) # 对图像做闭运算,迭代2次 cv2.imshow("4", tmp) # 窗口显示对二值化阈值处理后的图像进行闭运算后的结果 cv2.waitKey() cv2.destroyAllWindows() counr, _ = cv2.findContours(tmp, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) for contour in counr: # 遍历所有轮廓 if 200 < cv2.contourArea(c) < 500: # 至对符合涂卡面积的轮廓进行操作 M = cv2.moments(contour) # 获取轮廓的矩 x_center = int(M['m10'] / M['m00']) # 轮廓重心的横坐标 y_center = int(M['m01'] / M['m00']) # 轮廓重心的纵坐标 questio_num = get_question(y_center) # 判断涂卡的位置属于哪个题目 res = get_result(x_center) # 判断涂卡位置属于哪个选项 result[questio_num] = res # 记录答题者在改题目下的选项 for key in result.keys(): # 遍历答题者的答案 print("第", str(key), "题:", result[key])
四、形态学操作
4.1. 膨胀操作
1.膨胀操作前,需要二值化图像
2.膨胀操作可以让颜色值大的像素变得更粗 #==白色更粗==
img = cv2.imread("11.jpg", 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
#类似于卷积核
dst = cv2.dilate(img, kernel)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
4.2. 腐蚀操作
腐蚀操作相反,唯一变化的也是 #==白色变细==
img = cv2.imread("11.jpg", 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv2.erode(img, kernel) #就这里函数不一样
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
4.3. 开操作
先腐蚀再膨胀;可以用于去噪,或将两个靠的很近的做切割操作分开。 (小的就被腐蚀掉了,就膨胀不回来了)
img = cv2.imread("10.jpg", 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, iterations=1)
#最后的iterations代表迭代次数,,就是这样的行为做几次
cv.imwrite("9.jpg", dst)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
4.4. 闭操作
先膨胀再腐蚀;;可以用于填坑,或将两个靠的很近但没连在一起的连起来。注意:
- 若想让目标在y方向上保持连通,x方向不去扰动,核可以给成 (3, 35) 这样的形式;
- 若想让目标在x方向上保持连通,y方向不去扰动,核可以给成 (35, 3) 这样的形式;
img = cv2.imread("10.jpg", 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) # 核大小不一定x、y一样
dst = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel, iterations=1)
cv.imwrite("21.jpg", dst)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
开闭操作的区别:
都是先创建一个核,,然后这个morphologyEx函数都可以直接构建开闭操作(就是把膨胀腐蚀放一起了,选择谁由后面参数决定)
注意:这些操作的图一般都是黑底白字
4.5. 梯度操作
膨胀操作 - 腐蚀操作
img = cv.imread("11.jpg", 0)
kernel = cv.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
# cv.imwrite("21.jpg", dst)
cv.imwrite("27.jpg", dst)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
4.6 礼帽操作
开运算图像 - 原图像 #提取图上噪点
img = cv.imread("10.jpg", 0)
kernel = cv.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
4.7. 黑帽操作
闭运算图像 - 原图像 #提取字内的噪点
img = cv.imread("10.jpg", 0)
kernel = cv.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
注:这几个都大抵一样,都是先创建核,不同的是在后括号里给的参数
五、滤波
5.1. 滤波基本概念与知识
什么是滤波:
图像可以看成一种二维信号,把指定范围内的信号进行处理的过程,叫做滤波;#简单来说就是把一段信号中的一些波不要,去掉。
滤波的种类
低通滤波,高通滤波,中通滤波,阻带滤波;
#低通滤波就是低频的通过保留下来,,过滤掉高频的; 高通同理;
#中通滤波就是把中间频率的通过保留下来,,过滤掉低频和高频; 阻带滤波则是跟中通相反。
低通滤波: 模糊图像,去噪 #把原来的信号分散开来 #因为是去掉高频的,就是变化快的,一般就是边缘信息,还有就是一些噪点,突然冒出的噪点往往是高频的;
高通滤波: 寻找边缘轮廓,提取边缘,提取轮廓; #把原来的信号聚集起来
#剩下那俩一般是提取特殊信号。
时域滤波
#简单来说就是信号是跟”位置”有关的,无论是时间位置还是空间位置;根据”位置”来处理信号,就是时域滤波。
频域滤波
#一般图像的边缘、轮廓变化快,梯度也大;脸部,脸的位置变化就慢,梯度就小;然后把变化慢的放在坐标左边,变化快的放在坐标右边(一维信号就是一维坐标,二维信号就是二维坐标),依次排列;有一点像素直方图的感觉,在这样的图上分析就是频域滤波。 #上面两者间是可以互相转换的,且一般频域效果较好
5.2. OpenCV里做卷积
src = cv2.imread(r"1.jpg")
kernel = np.array([[1, 1, 0], [1, 0, -1], [0, -1, -1]], np.float32) # 定义一个核
dst = cv2.filter2D(src, -1, kernel=kernel)
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)

这个核,就相当于是一个滤波,有点光是左上打进来的,保留左上的信息多一些,可以尝试改一下,左上角右下角数据换换,各方面的明亮就不一样了,可以其他的试试。
5.3. 常用滤波(都是时域滤波)
#前面4个是低通滤波,用于去噪; 后面2个是高通滤波
5.3.1 均值滤波
#像素拉直取平均值,把变化大的就弄平了
src = cv2.imread(r"1.jpg")
dst = cv2.blur(src, (5,5)) #这个(5,5)卷积核越大,对大的噪点越有用;也可以自己写卷积核
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)
5.3.2 中值滤波
src = cv2.imread(r"1.jpg")
dst = cv2.medianBlur(src, 5) #主要就是取中值
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)
5.3.3 高斯滤波
#中间高,两边低; 对高斯噪声效果很好,即随机在样本上撒点,是最常见的噪点
高斯核:

src = cv2.imread(r"1.jpg")
dst = cv2.GaussianBlur(src, (5, 5), 0) #高斯核"0"就是代表一个标准高斯核,若为其他,就是中间的峰值更低,模糊程度更大
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)
5.3.4 双边滤波
#用于椒盐噪声
src = cv2.imread(r"1.jpg")
dst = cv2.bilateralFilter(src,9,75,75) #本分区域额模糊了,部分地区没有
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)
5.3.5 Laplacian高通滤波
src = cv2.imread(r"1.jpg")
src = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) # 后面好像不用转灰度图也能下面的操作,就是不知道影响大不大
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) #定义一个核,可以把这个核打出来看,这是典型的高斯核,把信息向中集中,是轮廓更加清晰
dst = cv2.filter2D(src, -1, kernel=kernel)
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)

这就是上面那个核,可以看到是把信号往中间聚集。后面老师也把这个核叫做Laplacian锐化。
5.3.6 USM锐化 #可以边缘加强
src = cv2.imread(r"6.jpg")
dst = cv2.GaussianBlur(src, (5, 5), 0) #先用高斯滤波处理一下,再加权一下
dst = cv2.addWeighted(src, 3, dst, -2, 0) #"3"和"-2"这里的值加起来要等于1的效果是最好的;可以试试组合也为1的其他值
print(dst.shape)
cv2.imshow("src show", src)
cv2.imshow("dst show", dst)
cv2.waitKey(0)
5.4. 滤波去噪总结
1.去噪的过程大抵都是先低通滤波一下,,再高通滤波
2.一般都是用高斯滤波,,除非知道是椒盐噪点,就用双边滤波;其他的一般不用
六、图像金字塔
知识点
- 使用图像创建一个新水果: “橘子苹果”;
- 将要学习的函数有: cv2.pyrUp(),cv2.pyrDown(); #向上向下采样
- 高斯金字塔和拉普拉斯金字塔。
6.1. 高斯金字塔
都先高斯模糊一下,再向下采样,称之为高斯金字塔。
主要是把边缘信息模糊化,然后做图像的拼接;但是图像的拼接又要边缘信息,于是有了拉普拉斯金字塔的补充。
img = cv2.imread(r"32.jpg")
for i in range(3):
cv2.imshow(f"img{i}",img)
img = cv2.pyrDown(img) #下采样
cv2.waitKey(0)
img = cv2.imread(r"33.jpg")
for i in range(3):
cv2.imshow(f"img{i}",img)
img = cv2.pyrUp(img) #上采样
cv2.waitKey(0)
6.2. 拉普拉斯金字塔
拉普拉斯金字塔就是为了保留边缘信息;可以找回高斯金字塔下采样过程中损失的信息,但同时还是去噪了。
拉普拉斯金字塔由高斯金字塔计算得来: \(Li = Gi - PyrUp(G(i+1))\) 就是这一层的高斯金字塔减去下一层的上采样。
img = cv2.imread(r"32.jpg")
img_down = cv2.pyrDown(img)
img_up = cv2.pyrUp(img_down)
img_new = cv2.subtract(img, img_up)
# img_new = cv2.convertScaleAbs(img_new, alpha=10, beta=0)
#为了更容易看清楚,做了个提高对比度的操作,就是黑的更黑,白的更白;一般就是操作alpha这个参数
cv2.imshow("img_LP", img_new)
cv2.waitKey(0)
6.3. 图像无缝融合
融合步骤
1.读入两幅图像,苹果和橘子 2.构建苹果和橘子的高斯金字塔(6层) 3.根据高斯金字塔计算拉普拉斯金字塔 4.在拉普拉斯的每一层进行图像融合(苹 果的左边与橘子的右边融合) 5.根据融合后的图像金字塔重建原始图像。
import cv2
import numpy as np
A = cv2.imread('34.jpg')
B = cv2.imread('35.jpg')
G = A.copy() #复制一份A,
gpA = [G] #这里是把G整个内容当做一个元素放进gpA这个列表里,里面就一个元素
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G) #产生6层苹果高斯金字塔
G = B.copy()
gpB = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G) #产生6层橘子高斯金字塔
# generate Laplacian Pyramid for A
lpA = [gpA[5]] #保留了原来的第五层
for i in range(5, 0, -1): #倒着生成
GE = cv2.pyrUp(gpA[i])
L = cv2.subtract(gpA[i - 1], GE) #第一个就是第四层-第五层,
lpA.append(L) #苹果的拉普拉斯金字塔
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in range(5, 0, -1):
GE = cv2.pyrUp(gpB[i])
L = cv2.subtract(gpB[i - 1], GE)
lpB.append(L) #橘子的拉普拉斯金字塔
# Now add left and right halves of images in each level
LS = []
for la, lb in zip(lpA, lpB):
#这里可以把ndarray直接append进列表里,在单独索引某个值时,就只有数据
rows, cols, dpt = la.shape
ls = np.hstack((la[:, 0:cols // 2], lb[:, cols // 2:])) #这是各取一半
LS.append(ls)
# now reconstruct #接下来就是每一层融合
ls_ = LS[0]
for i in range(1, 6):
ls_ = cv2.pyrUp(ls_) #每一层上采样,
ls_ = cv2.add(ls_, LS[i]) #再加到每一层去
# image with direct connecting each half
real = np.hstack((A[:, :cols // 2], B[:, cols // 2:]))
# real = np.concatenate((image1[:, :cols // 2], image2[:, cols // 2:]), axis = 1) #也可以用np.concatenate((tuple), 维度)因为数据是(h,w,c),所以维度给1就是在 宽 上。
#real = np.concatenate((image1[:rows // 2], image2[rows // 2:]), axis = 0) #axis给0就是在 高 上;注意前面的切片也要在h维度上
cv2.imshow('Pyramid_blending.jpg', ls_)
cv2.imshow('Direct_blending.jpg', real)
cv2.waitKey(0)
注解一下np.vstack和np.hstack的区别:
x = np.arange(54).reshape(3,6,3)
y = np.arange(54, 0, -1).reshape(3, 6, 3)
print(x)
print("=======================")
z = np.vstack((x[:, :3], y[:, 3:])) #形状成了(6, 3, 3)
print(z)
print("===============")
z = np.hstack((x[:, :3], y[:, 3:])) #形状还是(3, 6, 3)
print(z)
七、直方图
直方图
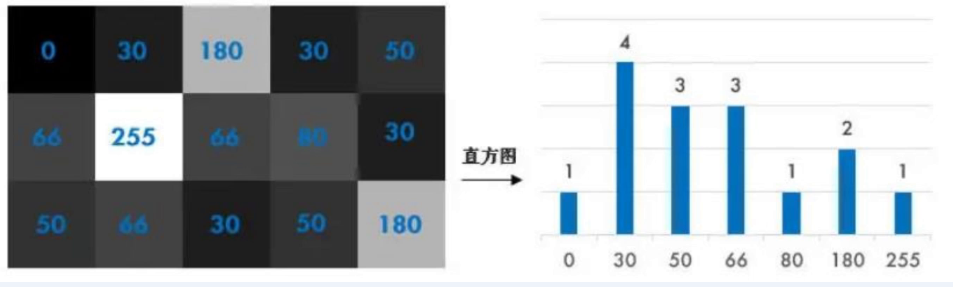
用来统计衡量各个像素值的个数,一般图片的像素直方图是成正态分布的。
7.1. 直方图的绘制
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('1.jpg')
img_B = cv2.calcHist([img], [0], None, [256], [0, 256])
#参数分别是图像、通道、掩码(如果没有就是对整个图画直方图)、切分成256个格子、每个格子的值是0~256
plt.plot(img_B, label='B', color='b')
img_G = cv2.calcHist([img], [1], None, [256], [0, 256])
plt.plot(img_G, label='G', color='g')
img_R = cv2.calcHist([img], [2], None, [256], [0, 256])
plt.plot(img_R, label='R', color='r')
plt.show()
7.2. 直方图均衡化
有全图均衡化、局部均衡化,一个是根据全图来算的,一个是类似于卷积核那种,局部去均衡化的,对一幅图上事物确有明暗区分的图效果较好。一定要打例子出来看
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('2.jpg', 0)
cv2.imshow("src", img)
his = cv2.calcHist([img], [0], None, [256], [0, 256])
plt.plot(his, label='his', color='r')
# plt.show()
dst = cv2.equalizeHist(img) #直方图全图均衡化
cv2.imshow("dst", dst)
cv2.imwrite("15.jpg", dst)
his = cv2.calcHist([dst], [0], None, [256], [0, 256])
plt.plot(his, label='his', color='b')
plt.show()
cv2.waitKey()
img = cv2.imread('12.jpg', 0)
cv2.imshow("src", img)
dst1 = cv2.equalizeHist(img)
cv2.imshow("dst1", dst1)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
#说是多了(8*8)的核
dst2 = clahe.apply(img)
#上面两行是实现了局部均衡化,就比全局多这两行代码;那个雕像脸部会没有那么亮,周围亮一些;自己打来看看局部和全局的区别
cv2.imshow("dst2", dst2)
cv2.waitKey(0)
7.3. 2D直方图
在前面的部分我们介绍了如何绘制一维直方图,之所以称为一维,是因为我们只考虑了图像的一个特征:灰度值。但是在2D直方图中我们就要考虑两个图像特征。对于彩色图像的直方图通常情况下我们需要考虑每个的颜色(Hue) 和饱和度(Saturation) 。根据这两个特征绘制2D直方图。
这种需要将图片放进HSV,关注H色彩和S饱和度。
img = cv2.imread('3.jpg')
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
#h最大180;s最大255
cv2.imshow("hist",hist)
cv2.waitKey(0) #得到图横轴就是h,纵轴就是s;每种颜色在每个亮度下就是一个点
7.4. 直方图反投影
-
它可以用来做图像分割,或者在图像中找寻我们感兴趣的部分。简单来说,它会输出与输入图像(待搜索)同样大小的图像,其中的每一个像素值代表了输入图像上对应点属于目标对象的概率。用更简单的话来解释,输出图像中像素值越高(越白)的点就越可能代表我们要搜索的目标(在输入图像所在的位置)。这是一个直观的解释。直方图投影经常与camshift算法等一起使用。
-
我们要查找的对象要尽量占满这张图像(换句话说,这张图像上最好是有且仅有我们要查找的对象)。最好使用颜色直方图,因为一个物体的颜色要比它的灰度能更好的被用来进行图像分割与对象识别。接着我们再把这个颜色直方图投影到输入图像中寻找我们的目标,也就是找到输入图像中的每一个像素点的像素值在直方图中对应的概率,这样我们就得到一一个概率图像,最后设置适当的阈值对概率图像进行二值化。
"""比较针对去找草坪这种具有单一颜色的"""
roi = cv2.imread('25.jpg')
hsv = cv2.cvtColor(roi,cv2.COLOR_BGR2HSV)
target = cv2.imread('26.jpg')
hsvt = cv2.cvtColor(target,cv2.COLOR_BGR2HSV) #都先转HSV格式
roihist = cv2.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] ) #再2D直方图
cv2.normalize(roihist,roihist,0,255,cv2.NORM_MINMAX)
#归一化后的直方图便于显示,归一化之后就成了0到255之间的数;cv2.NORM_MINMAX对数组的所有值进行转化,使它们线性映射带最小值和最大值之间
dst = cv2.calcBackProject([hsvt],[0,1],roihist,[0,180,0,256],1) #这就是直方图反投影
disc = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5))
#类似于做卷积核
dst=cv2.filter2D(dst,-1,disc)
ret,thresh = cv2.threshold(dst,50,255,0)
thresh = cv2.merge((thresh,thresh,thresh)) #别忘了是三通道图,整合在一起
res = cv2.bitwise_and(target,thresh)
res = np.hstack((target,thresh,res))
cv2.imshow('img',res)
cv2.waitKey(0) #说是中间那个图有点类似掩码,两个再组合生成第三个;很多懂不起了啊
7.5. 总结
cv2.calcHist() #直方图
dst = cv2.equalizeHist(img) #直方图全图均衡化
cv2.calcBackProject() #直方图反投影
八、模板匹配
“梅西踢球,加里奥金币那个”。这还有C++的代码。
import cv2
img = cv2.imread('13.jpg', 0) # 不一定是要灰度图,但这会减少计算量,看自己的情况决定,有颜色可能更准确,也可能会更死板
template = cv2.imread('14.jpg', 0)
h, w = template.shape
# 除了这个cv2.TM_CCOEFF算法,还有其它的共计6个算法
res = cv2.matchTemplate(img, template, cv2.TM_CCOEFF) #根绝这个最后一个值的算法,确定下面到底要哪一个
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
#通过这一个函数就获得了“最小值、最大值、最小值的位置、最大值的位置”
# 如果用了cv2.TM_CCOEFF_NORMED,归一化后,最大值就可以看成相似度,最大值在0-1之间,越接近于1,越匹配。
bottom_right = (max_loc[0] + w, max_loc[1] + h)
cv2.rectangle(img, max_loc, bottom_right, 255, 2)
# cv2.imwrite("35.jpg", img)
cv2.imshow("img", img)
cv2.waitKey(0)
上面的代码只能获取最大最小,要找一个范围的话,就要自己定义查找条件,如下:
import cv2
import numpy as np
img_rgb = cv2.imread('15.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('16.jpg', 0)
h, w = template.shape
# cv2.TM_CCOEFF_NORMED 比起 cv2.TM_CCOEFF 的结果归一化了,然后就好用0-1的thread进行筛选,最好匹配是 1
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
# 取匹配程度大于%80的坐标
threshold = 0.8
loc = np.where(res >= threshold) #自定义查找的条件
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0, 0, 255), 2)
cv2.imshow('img', img_rgb)
cv2.waitKey(0)
九、轮廓与边缘
9.1. 定义
边缘:可能会断断续续,不一定是闭合的。
轮廓:把脸框出来那个圆或者矩形都可以叫轮廓,它是闭合的。
9.2. 图像梯度
-
Sobel, Scharr 和Laplacian梯度滤波器 #都是高通滤波器,跟梯度相关
-
Scharr 滤波器是对Sobel滤波器的改进版本
-
Sobel, Scharr实就是求一阶或二阶导数。Scharr 是对Sobel (使用小的卷积核求解求解梯度角度时)的优化。Laplacian 是求二阶导数
-
计算梯度值和方向
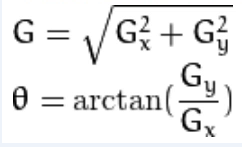
-
Sobel算子是高斯平滑与微分操作的结合体,所以它的抗噪声能力很好
Sobel算子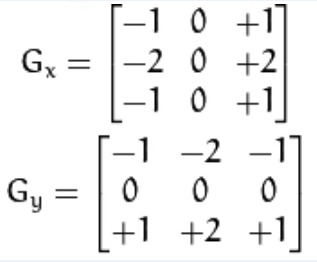
Gx在它的x方向上可以求导,高斯分布;在y方向上又可以模糊。故补充一下,在图片Gy,在它的x方向模糊;在y方向上求导,高斯分布。所以最后就可以达到整张图,同时在x、y方向上既求导,高斯分获取边缘信息,又模糊去噪。
Scharr算子
我们一般都用Scharr算子,它只是Sobel算子的改良,效果更好。
Laplacian算子 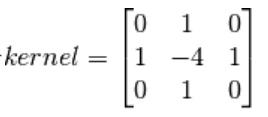
拉普拉斯算子可以使用二阶导数的形式定义,可假设其离散实现类似于二阶Sobel导数,事实上, OpenCV在计算拉普拉斯算子时直接调用Sobel算子
实例
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('4.jpg', 0)
laplacian = cv2.Laplacian(img, cv2.CV_64F) #拉普拉斯算子
sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=5) #Sobel算子
sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=5)
scharrx = cv2.Scharr(img, cv2.CV_64F, 1, 0) #Scharr算子
scharry = cv2.Scharr(img, cv2.CV_64F, 0, 1)
images = [img, laplacian, sobelx, sobely, scharrx, scharry]
images_name = ["img", "laplacian", "sobelx", "sobely", "scharrx", "scharry"]
for i in range(6):
plt.subplot(3, 2, i+1)
plt.title(images_name[i])
plt.imshow(images[i], cmap="gray")
plt.axis("off")
plt.show()
Sobel 边缘检测,看这里。(车牌提取那里也看到了)
Laplace边缘提取
用它也可以提取边缘,类似于Canny,下面是opencv自带的sample。
#!/usr/bin/env python
'''
This program demonstrates Laplace point/edge detection using
OpenCV function Laplacian()
It captures from the camera of your choice: 0, 1, ... default 0
Usage:
python laplace.py <ddepth> <smoothType> <sigma>
If no arguments given default arguments will be used.
Keyboard Shortcuts:
Press space bar to exit the program.
'''
import sys
import cv2
import numpy as np
def main():
# Declare the variables we are going to use
ddepth = cv2.CV_16S
smoothType = "MedianBlur"
sigma = 3
if len(sys.argv)==4:
ddepth = sys.argv[1]
smoothType = sys.argv[2]
sigma = sys.argv[3]
# Taking input from the camera
cap=cv2.VideoCapture(0)
# Create Window and Trackbar
cv2.namedWindow("Laplace of Image", cv2.WINDOW_AUTOSIZE)
cv2.createTrackbar("Kernel Size Bar", "Laplace of Image", sigma, 15, lambda x:x)
# Printing frame width, height and FPS
print("=="*40)
print("Frame Width: ", cap.get(cv.CAP_PROP_FRAME_WIDTH), "Frame Height: ", cap.get(cv.CAP_PROP_FRAME_HEIGHT), "FPS: ", cap.get(cv.CAP_PROP_FPS))
while True:
# Reading input from the camera
ret, frame = cap.read()
if ret == False:
print("Can't open camera/video stream")
break
# Taking input/position from the trackbar
sigma = cv2.getTrackbarPos("Kernel Size Bar", "Laplace of Image")
# Setting kernel size
ksize = (sigma*5)|1
# Removing noise by blurring with a filter
if smoothType == "GAUSSIAN":
smoothed = cv2.GaussianBlur(frame, (ksize, ksize), sigma, sigma)
if smoothType == "BLUR":
smoothed = cv2.blur(frame, (ksize, ksize))
if smoothType == "MedianBlur":
smoothed = cv2.medianBlur(frame, ksize)
# Apply Laplace function
laplace = cv2.Laplacian(smoothed, ddepth, 5)
# Converting back to uint8
result = cv2.convertScaleAbs(laplace, (sigma+1)*0.25)
# Display Output
cv2.imshow("Laplace of Image", result)
k = cv2.waitKey(30)
if k == 27:
return
if __name__ == "__main__":
print(__doc__)
main()
cv2.destroyAllWindows()
9.3. Canny边缘提取算法
●Canny算法是一-种边缘提取算法
●学会使用OpenCV调用Canny算法
●Canny算法的基本原理
img = cv2.imread("1.jpg", 0)
cv2.imshow('Canny2', img)
img1 = cv2.GaussianBlur(img, (5, 5), 40) #40是高斯模糊的方差,越小保留的东西越多。
#先用了高斯模糊,如不用,会有很多东西,就不仅仅是边缘,可以对比一下
canny1 = cv2.Canny(img1, 50, 150)
img2 = cv2.GaussianBlur(img, (5, 5), 0) #两个可以对比一下看;因为是要边缘,所以一般来说这个方差会稍微给大一点,让中间的东西少一些。
canny2 = cv2.Canny(img2, 50, 150)
cv2.imshow('Canny1', canny1)
cv2.imshow('Canny2', canny2)
cv2.waitKey(0)
9.3.1 原理详解
步骤
- 彩色图像转换为灰度图像
- 高斯滤波,滤除噪声点 #以上两步是Canny算法外做的
- 计算图像梯度,根据梯度计算边缘幅值与角度 #用前面的算子
- 非极大值抑制 #留一个最好的边缘,其他的丢掉,使其厚度为1
- 双阈值边缘连接处理 #判断输出的哪些线连在一起
- 二值化图像输出结果
9.3.2 非极大值抑制
非极大值抑制是一种边缘稀疏技术,非极大值抑制的作用在于”瘦”边。对图像进行梯度计算后,仅仅基于梯度值提取的边缘仍然很模糊。而非极大值抑制则可以帮助将局部最大值之外的所有梯度值抑制为0。
- 将当前像素的梯度强度与沿正负梯度方向,上的两个像素进行比较;
- 如果当前像素的梯度强度与另外两个像素相比最大,则该像素点保留为边缘点,否则该像素点将被抑制。
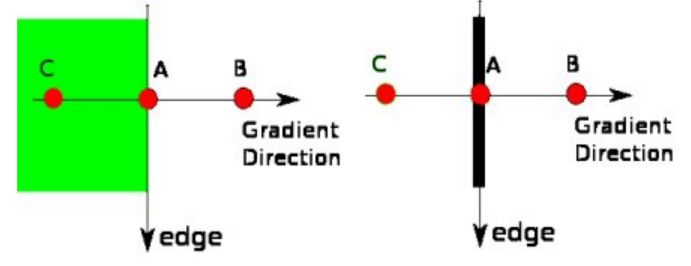
9.3.3 双阈值边缘连接处理
这个阶段决定哪些边缘是边缘,哪些边缘不是边缘。为此,我们需要两个阈值,minVal和maxVal。 强度梯度大于maxVal的边缘肯定是边缘,而minVal以 下的边缘肯定是非边缘的,因此被丢弃.两者之间的值要判断是否与真正的边界相连,相连就保留,不相连舍弃。
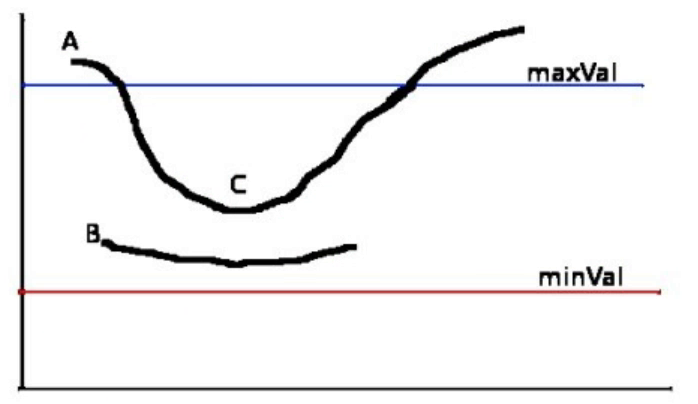
上图的横坐标代表像素值,纵坐标代表梯度;maxVal和minVal就代表cv2.Canny()里需要设置的后面两个参数;
-
如果线全在maxVal以下就舍弃,全在maxVal以上就保留;
-
如果线两头在maxVal以上,且最小值在maxVal与minVal之间,线也全部保留;
-
如果线只有一头在maxVal以上,就只保留maxVal之上的部分,其它的舍弃;
-
如果线两头都在maxVal以上,但最小值在minVal之下,那就只保留maxVal以上的两头部分,其它中间的就全部舍弃。
故有一些边缘的应该连接起来,但是没有,就可以尝试把大值设小一点。
9.3.4 实例:提取人脸边缘
很多时候可以下把image拿到下面画一个轮廓,然后再提取
img = cv2.imread("6.jpg", 0)
cv2.imshow('Canny2', img) #灰度图
img = cv2.convertScaleAbs(img, alpha=6, beta=0)
#提高对比度,为了使白的边缘更白,不然在下面操作时因为脸边缘很淡,直接被模糊掉了
cv2.imshow('Abs', img)
img = cv2.GaussianBlur(img, (5, 5), 0) #高斯模糊
canny = cv2.Canny(img, 50, 150)
canny = cv2.resize(canny, dsize=(500, 500))
cv2.imshow('Canny', canny)
cv2.waitKey(0)
9.4. 轮廓
去看这里关于它的详解,有CHAIN_APPROX_SIMPLE与CHAIN_APPROX_NONE参数的区别。
findContours可以返回轮廓的层次信息,用不同的这cv2.RETR_TREE位置的方法。(上面的链接这个参数也写了的,有图,比较详细,用这之前去看看,还有这个教程,但层级关系好像不是很好用,==cv2.RETR_EXTERNAL可以只查看外轮廓,被包含在内部的就不会被查找==)
更具体的一个使用可以去看专利撰写里面,有对边缘轮廓的一个更细致的前处理和轮廓删选处理。
img = cv2.imread('17.jpg')
# 老版本
#imggray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 先灰度化
#ret, thresh = cv2.threshold(imggray, 127, 255, 0) # 再二值化
# 现在看情况,一般先做一个高斯模糊去噪,再用自适应二值化
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_gauss = cv2.GaussianBlur(img_gray, (5, 5), 0) # 高斯模糊(核大小看实际情况)
img_mask = cv2.adaptiveThreshold(img_gauss, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 15, 5) # 自适应二值化
contours, _hierarchy = cv2.findContours(img_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 倒数第二个参数就是有点将各个轮廓关系弄成关系树 (试试看 cv2.RETR_EXTERNAL 有惊喜)
# 最后一个参数若改成cv2.CHAIN_APPROX_NONE,唯一变化的就是下面这行的结果,为720,是构成轮廓的所有像素点
print(len(contours[0])) # 得到的是4;轮廓是一个列表,取出第一个值再取len(),得到的是构成这个轮廓的点的个数
# 得到轮廓和层次结构;然后一个图可能会有多个轮廓,所以这个contours是一个list
# 画单通道的图(二值化后的图),颜色给 (155, 155, 155)
cv2.drawContours(img, contours, -1, color=(0, 255, 0), thickness=3) # 画轮廓(可以不要返回值,它会修改原图img)
# 第三个参数代表画第几个轮廓,负数代表画所有,正数就是要第几个就写几;再就是颜色;再就是线宽,若为负值,就是填充(这样就可以下面9.9制作对象的掩码)
cv2.imshow("img_contour", img)
cv2.waitKey(0)
查找轮廓的函数findContours的参数详细信息,以及opencv版本3和版本4,这个函数参数返回值是不一样的,版本3是返回的3个值,版本4是返回的2个值,具体看这里。
9.5. 轮廓近似
将轮廓形状近似到另外一种由更少点组成的轮廓形状,新轮廓点的数目由我们设定的准确度来决定。cv2.approxPolyDP 3.2.2. 透视变换 中有用到这去计算矩形端点
img = cv2.imread('19.jpg')
imggray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(imggray,127,255,0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
epsilon = 60 #最大偏离的像素值,越小越拟合原来的图形,越大就会舍弃掉一些边的拟合(试试10,30,60的区别)
approx = cv2.approxPolyDP(contours[0], epsilon, True)
#注意contours是一个列表
img_contour= cv2.drawContours(img, [approx], -1, (0, 255, 0), 3)
cv2.imshow("img_contour", img_contour)
cv2.waitKey(0)
9.6. 面积、周长、重心
img = cv2.imread('18.jpg', 0)
ret, thresh = cv2.threshold(img, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
M = cv2.moments(contours[0]) # 先算一个矩
cx, cy = int(M['m10'] / M['m00']), int(M['m01'] / M['m00'])
print("重心:", cx, cy) #可能一些跟踪算法时,要用到某些不变的量
area = cv2.contourArea(contours[0])
print("面积:", area)
perimeter = cv2.arcLength(contours[0], True)
print("周长:", perimeter)
9.7. 凸包与凸性检测
- 凸包与轮廓近似相似,但不同,虽然有些情况下它们给出的结果是一样的。函数cv2.convexHull()可以用来检测一一个曲线是否具有凸性缺陷,并能纠正缺陷。一般来说,凸性曲线总是凸出来的,至少是平的。如果有地方凹进去了就被叫做凸性缺陷。
- 函数cv2.isContourConvex()可以可以用来检测一个曲线是不是凸的。它只能返回True或False。
对一个图形,图内任意两点的连线上的所有点都在图形内,这个图就是凸的,如正五边形、正六边形;反之这个图就是非凸的,如五角星。
-
凸函数:像开口向上的二次函数的图形那种
-
凹函数:像开口向下的二次函数的图形那种
9.7.1 碰撞检测
两个凸图形,在x、y轴上的投影能直接看出是否有重合(即碰撞),然而有一个非凸图形都是无法这样确定的,需要画出那非凸图形的外切圆来近似处理。
img = cv2.imread('18.jpg')
imggray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imggray, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
hull = cv2.convexHull(contours[0]) #获取这个图形的最小凸起图形
print(cv2.isContourConvex(contours[0]), cv2.isContourConvex(hull))
#isContourConvex用来判断后面的图形是否为凸图形,是则返回True,反之False
img_contour = cv2.drawContours(img, [hull], -1, (0, 0, 255), 3)
cv2.imshow("img_contour", img_contour)
cv2.waitKey(0)
9.7.2 外接圆|==最小外接矩形==(可以是斜的)
外接圆和矩形是获取不规则图形最简单的凸图形了
opencv中找轮廓要注意,二值图时,是在黑色背景里找白色的物体。
img = cv2.imread('20.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_gauss = cv2.GaussianBlur(img_gray, (5, 55), 0) # 高斯模糊(非必须)
# ret, thresh = cv2.threshold(img_gauss, 127, 255, 0) # 超参不好给,也可考虑这种
img_mask = cv2.adaptiveThreshold(img_gauss, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 15, 5) # 自适应二值化
contours, hierarchy = cv2.findContours(img_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#注意这个contours,图像一般不会是只有一个物体轮廓,可以用for循环把它都画出来,然后通过设定下面x,y,w,h的阈值进行筛选,下面值展示了第一个轮廓
# 边界矩形(类似于标注的bbox,绝对是正的,不会是倾斜的矩形)
x, y, w, h = cv2.boundingRect(contours[0])
img_contour = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 最小外接矩形(可以是倾斜的)
min_rect = cv2.minAreaRect(contours[0])
box = cv2.boxPoints(min_rect)
box = np.intp(box) # (np.int0 is deprecated by NumPy 1.24) 转成整型
cv2.drawContours(img, [box], 0, (0, 255, 0), 2) # 这里因为box少了一层,所有用的[box],里面就一个值,所以索引取0
cv2.polylines(img, [box], isClosed=True, color=(0, 0, 255), thickness=2) # 这是另外一种画轮廓的方法
# 最小外接圆
(x, y), radius = cv2.minEnclosingCircle(contours[0])
center = (int(x), int(y))
radius = int(radius)
img_contour = cv2.circle(img, center, radius, (255, 0, 0), 2)
# 最小外接三角形 (还没用过,具体用到再去看)
area, t = cv2.minEnclosingTriangle(contours[0]) # 计算最小三角包围框
cv2.imshow("img_contour", img_contour)
cv2.waitKey(0)
Tips:
- min_rect = cv2.minAreaRect(contours[0]) 得到的rect是一个元祖,其中
- min_rect[0]是这个矩形的中心点(x, y);
- min_rect[1]是这是矩形的(w, h),注意顺序,很重要,决定第三个值的旋转角度;
- min_rect[2]是得到矩形的旋转角度,角度的计算方式,opencv4.5版本和之前的版本是不同的,参见这里。(去看9.12. 实例:提取螺栓防松动线,里面有我自己的解释)
- box = cv2.boxPoints(min_rect) # 这是直接帮我们算出倾斜矩形的四个点坐标,方便画出来。(然后这也是用cv2.drawContours去画,注意看上面第18行的写法)
- box[0] 是一个点的坐标,左上角 # 一定要去画出来看,因为不同的图,和视角,可能这个点的起点是在视觉上的左下角。
- box[1] 右上角
- box[2] 右下角
- box[3] 左下角 # 整体是一个逆时针的方向
9.7.3 椭圆|直线拟合——判断图形的方向
直线和最小椭圆用来判断图形的方向
img = cv2.imread('20.jpg')
imggray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imggray, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 椭圆拟合
ellipse = cv2.fitEllipse(contours[0])
cv2.ellipse(img, ellipse, (255, 0, 0), 2)
# 直线拟合
h, w, _ = img.shape
[vx, vy, x, y] = cv2.fitLine(contours[0], cv2.DIST_L2, 0, 0.01, 0.01)
lefty = int((-x * vy / vx) + y)
righty = int(((w - x) * vy / vx) + y)
cv2.line(img, (w - 1, righty), (0, lefty), (0, 0, 255), 2)
cv2.imshow("img_contour", img)
cv2.waitKey(0)
9.7.4 将倾斜的矩形旋转正
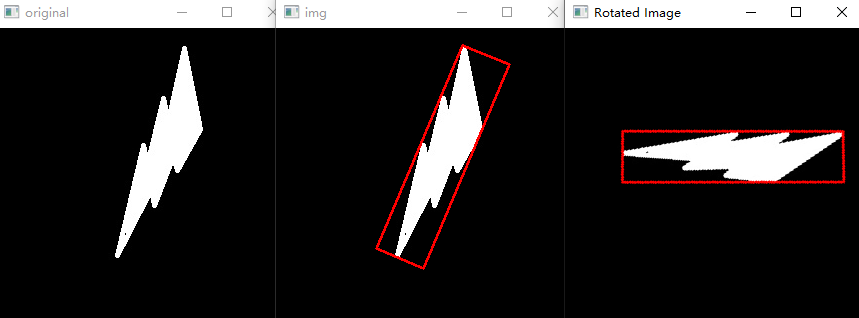
import cv2
import numpy as np
# 读取图像
image = cv2.imread("21.jpg")
cv2.imshow("original", image)
grayImg = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# TODO: 针对其它的复杂的图,可能需要先做高斯模糊去噪+边缘检测,再去查找下面寻找轮廓
ret, thresh = cv2.threshold(grayImg, 127, 255, 0)
# 寻找轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 计算所有轮廓的最小外接矩形的面积,并找到面积最大值的索引(以面积最大的这块区域来旋转)
areas = [cv2.contourArea(contours[i]) for i in range(len(contours))]
areas = np.asarray(areas)
max_area_index = np.argmax(areas)
# 计算角度(参数及角度计算说明看9.7.2)
min_rect = cv2.minAreaRect(contours[max_area_index])
center_x, center_y = round(min_rect[0][0]), round(min_rect[0][1])
# 或者写成 (center_x, center_y) = round(rect[0])
min_rect_w, min_rect_h = round(min_rect[1][0]), round(min_rect[1][1])
if min_rect_w > min_rect_h:
angle = min_rect[2]
else:
angle = -(90 - min_rect[2])
# 画出原始最大的倾斜的box
box = cv2.boxPoints(min_rect)
box = np.intp(box)
cv2.drawContours(image, [box], 0, (0, 0, 255), 2)
cv2.imshow("img", image)
# 旋转图像以摆正矩形
# 注意若整个图像是长宽比过小的竖着的图案,旋转后,它的原本竖着的高就变成了横着的长,就会超出原本的图案
(h, w) = image.shape[:2]
# center = (w // 2, h // 2)
center = (center_x, center_y) # 这是最小外接矩形的中心,是在整张图上的坐标
M = cv2.getRotationMatrix2D(center, angle, scale=1) # 这得到的是整张图的变换矩阵,一般的形状是:(2, 3) 没有第三个 [0, 0, 1]。局部的倾斜框是不能乘这个变换矩阵的。
rotated = cv2.warpAffine(image, M, (w, h))
#cv2.imshow('Rotated Image', rotated)
# 下面是计算出图像旋转摆正后目标的最小外接矩形框的坐标
# 上面已经有了旋转矩阵M(2, 3),因为不是绕原点旋转,有平移坐标,
# 1.0那就先给旋转矩阵加一个齐次坐标
new_M = np.vstack((M, np.array([0, 0, 1]))) # new_M(3, 3),第3行就是[0, 0, 1]
# 2.0由于变换是 变换矩阵 × 坐标 ,变换矩阵在前,所要把box从(4, 2)变成(2, 4),一列是一个点的坐标,
new_box = np.transpose(box, (1, 0)) # box(4, 2) -> new_box(2, 4)
# 3.0同样要给坐标加上齐次坐标,这里相当于是一个坐标(x0,y0, 1),因为书写原因,这其实是一列,所以4个坐标4列,就加4个1
new_box = np.vstack((new_box, np.array([1, 1, 1, 1]))) # new_box(3, 4),最后一行全是1
# 4.0特别注意变换矩阵一定是在乘号的左边
pts = np.dot(new_M, new_box) # pts(3, 4), 同样最后一行还是全是1
# 5.0把齐次的最后一行去掉,再把坐标从一个坐标一列的形式变回为原来的一个坐标一行
pts = np.transpose(pts[:2], (1, 0)) # shape=(4, 2)
pts = np.intp(pts)
cv2.drawContours(rotated, [pts], 0, (255, 0, 255), 2)
cv2.imshow('Rotated Image', rotated)
# 从摆正后的图中根据新算的坐标把目标对象抠出来
target_img = rotated[min(pts[:, 1]): max(pts[:, 1]), min(pts[:, 0]): max(pts[:, 0])]
cv2.imshow("target_img", target_img)
cv2.waitKey(0)
注:
- 坐标计算旋转矩阵看一下这个教程。
- 目标的最小外接矩形的坐标在图形旋转摆正后的新的坐标的计算,要用到上一条的教程。
- 一定注意,==旋转(变换)矩阵一定是在乘号的左边==,右边才是坐标,且要把坐标变换成一个坐标一列的形式。
- 一般的旋转矩阵都是绕原点旋转,这上面得到的M矩阵不是绕的原点,切记;那么就存在平移的问题,就涉及到齐次坐标。
9.8. 轮廓性质
●边界矩形的宽高比
\[Aspect Ratio = Width/Height\]x,y,w,h = cv2.boundingRect(contour)
aspect_ratio = float(w)/h
●轮廓面积与边界矩形面积的比
\[Extent = Object Area/Bounding Rerangle Area\]area = cv2.contourArea(contour)
x,y,,w,h = cv2.boundingRect(contour)
rect_area = w*h
extent = float(area)/rect_area
●轮廓面积与凸包面积的比
\[Solidity = Contour Area/Convex Hull Area\]area = cv2.contourArea(contour)
hull = cv2.convexHull(contour)
hull_area = cv2.contourArea(hull)
solidity = float(area)/hull_area
●与轮廓面积相等的圆形的直径
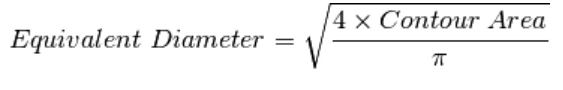
area = cv2.contourArea(contour)
equi_diameter = np.sqrt(a*area/np.pi)
●对象的方向
下面的方法还会返回长轴和短轴的长度
(x, y), (MA,ma), angle = cv2.fitEllipse(contour)
9.9. 对象掩码
用于获取构成对象的所有像素点
img = cv2.imread('18.jpg')
imggray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imggray, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
mask = np.zeros(imggray.shape, np.uint8)
cv2.drawContours(mask, contours, 0, 155, -1) #参数含义上面讲了
pixelpoints = np.transpose(np.nonzero(mask))
print(pixelpoints)
cv2.imshow("mask", mask)
cv2.waitKey(0)
最大值和最小值及他们的位置
min_val,max_val,min_loc,max_loc=cv2.minMaxLoc(imggray, mask = mask)
9.10. 形状匹配(通过轮廓)
img1 = cv2.imread('20.jpg', 0)
img2 = cv2.imread('21.jpg', 0)
ret, thresh = cv2.threshold(img1, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, 2, 1)
cnt1 = contours[0]
ret, thresh2 = cv2.threshold(img2, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh2, 2, 1)
cnt2 = contours[0]
ret = cv2.matchShapes(cnt1, cnt2, 1, 0.0) #主要是这函数
print(ret)
都是两个图,灰度化,再二值化,找到轮廓,将两个轮廓通过函数对比;值为0说明完全匹配,值越大,匹配度越低。
9.11. 实例:提取车牌号码
①高斯模糊 #所有操作前先来一遍高斯模糊去噪
②图片灰度化
③Sobel算子 #找轮廓
④图像二值化
⑤闭操作
⑥膨胀操作
⑦中值滤波
⑧查找轮廓
⑨判断车牌区域
# 读取图片
rawImage = cv2.imread("22.jpg")
# 高斯模糊,将图片平滑化,去掉干扰的噪声
image = cv2.GaussianBlur(rawImage, (3, 3), 0)
# 图片灰度化
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
# Sobel算子(X方向)
Sobel_x = cv2.Sobel(image, cv2.CV_16S, 1, 0)
# Sobel_y = cv2.Sobel(image, cv2.CV_16S, 0, 1)
absX = cv2.convertScaleAbs(Sobel_x) # 转回uint8;;提高对比度,使轮廓更明显
# absY = cv2.convertScaleAbs(Sobel_y)
# dst = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
image = absX
# 二值化:图像的二值化,就是将图像上的像素点的灰度值设置为0或255,图像呈现出明显的只有黑和白
ret, image = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)
# 闭操作:闭操作可以将目标区域连成一个整体,便于后续轮廓的提取。
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (17, 5))
image = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernelX)
# 膨胀腐蚀(形态学处理)
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (20, 1))
kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 19))
image = cv2.dilate(image, kernelX)
image = cv2.erode(image, kernelX)
image = cv2.erode(image, kernelY)
image = cv2.dilate(image, kernelY)
# 平滑处理,中值滤波
image = cv2.medianBlur(image, 15)
cv2.imshow("...2.", image)
# 查找轮廓
contours, w1 = cv2.findContours(image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for item in contours:
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
if weight > (height * 2): #直接车牌宽高比来的
# 裁剪区域图片
chepai = rawImage[y:y + height, x:x + weight]
# cv2.imshow('chepai' + str(x), chepai)
# 绘制轮廓
image = cv2.drawContours(rawImage, contours, -1, (0, 0, 255), 3)
cv2.imshow('image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
9.12. ==实例:提取螺栓防松动线==
首先这个例子是针对防松动线是用红色画的,步骤:
- 如果一张大图,用目标检测的手段把螺栓找出来先;
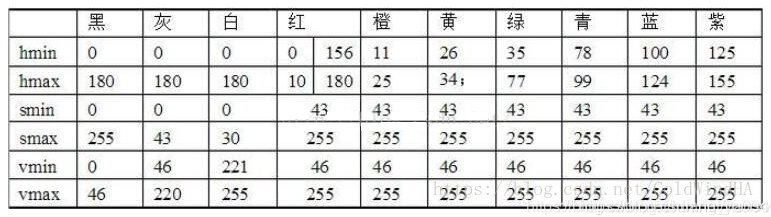
- 提取红色的线:先转换成HSV色彩空间,然后循环每个像素通过红色的hsv的值来找到指定区域,数值参考如下:(opencv中的hsv值域是[0, 255],注意:每个程序定义的HSV中h,s,v 三个值的值域可能不相同)
- 查找轮廓并筛选,再把轮廓画出来,同时获得这些轮廓的最小外接矩形(大抵是倾斜的),以及其倾斜的角度,然后通过角度来判断是否对齐。
(在c++版本里,我还写了这个操作对应的c++版本)(注意用4.5以上版本的opencv,主要是求角度的api不同版本之间有差异)
import cv2
import numpy as np
from termcolor import colored
def extract_rad_area(src_img):
"""循环每一个像素值,值红色区域的就置为255,其它就是默认的0"""
# 这个算法,在opencv中就有实现,效果一样,看前面笔记 “例如:提取图中的文字”,核心API是 cv2.inRange
h, w, c = src_img.shape
img_hsv = cv2.cvtColor(src_img, cv2.COLOR_BGR2HSV)
img_h, img_s, img_v = cv2.split(img_hsv)
out_img = np.zeros((h, w))
for x in range(h):
for y in range(w):
point_h = img_h[x, y]
point_s = img_s[x, y]
point_v = img_v[x, y]
# hsv红色范围
if ((point_h > 156 and point_h < 180) and (point_s > 43 and point_s < 255) and (
point_v > 46 and point_v < 255)):
out_img[x, y] = 255
return out_img
def find_filter_contours(threshold_img):
"""找出所有的轮廓,并设置条件过滤一些"""
threshold_img = threshold_img.astype(np.uint8)
contours, hierarchy = cv2.findContours(threshold_img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
out_contours = []
for contour in contours:
rect = cv2.boundingRect(contour) # x, y, w, h
weight = rect[2]
height = rect[3]
if weight < 10 or height < 10: # 这个换位可以酌情修改
continue
out_contours.append(contour)
return tuple(out_contours)
def draw_obtain(src_img, contours):
out_img = src_img.copy()
centers = []
angles = []
for contour in contours:
min_rect = cv2.minAreaRect(contour)
center_x, center_y = round(min_rect[0][0]), round(min_rect[0][1]) # (x, y)
centers.append((center_x, center_y))
min_rect_w, min_rect_h = round(min_rect[1][0]), round(min_rect[1][1]) # (w, h) 注意顺序
# 4.5版本定义为,x轴顺时针旋转最先重合的边为w,angle为x轴顺时针旋转的角度,angle取值为(0,90]。
# 所以当w>h时,得到的值就是我们要的,当w<h时,我们还是希望以长边为计算角度,然后它就是从x轴逆时针更快接触到长的一边,
# 因为x轴逆时针,所以前面加个负号,值就是opencv算的角的补角,为 -(90 - min_rect[2])
if min_rect_w > min_rect_h: # 当最先遇到的长边是w时,这个角度我们才认可
angle = min_rect[2] # 倾斜角度
else:
angle = -(90 - min_rect[2])
angles.append(angle)
print(f"center_position: {center_x, center_y}",
f"min_rect_h_w: {min_rect_h, min_rect_w}", f"angle: {angle:.2f}°", sep="\t\t")
# 画出中心点
cv2.circle(out_img, (center_x, center_y), 5, (0, 255, 255), -1)
# 画出最小外接矩形
box = cv2.boxPoints(min_rect)
box = np.int0(box)
cv2.drawContours(out_img, [box], 0, (0, 255, 0), 2)
return out_img, centers, angles # 返回画出的图形和各个轮廓的中心点以及角度
if __name__ == '__main__':
# 红色标记
"""
1° = π / 180 ≈ 0.01745 rad
1rad = 180 / π ≈ 57.30°
images:
01.jpg:画的一条完整连续的线;
02.jpg:画的一条一个方向的线,中间有间断;
03.jpg:跟02.jpg差不多是一样的,只是将角度倾斜了;
04.jpg:03.jpg的角度,然后螺栓、螺母上的线没有对齐了
------------ 以上是一个方向的螺栓,下面是另外一个方向的 --------------------
05.jpg:防松动线没对齐,然后换了一个朝向以验证角度
06.jpg:防松动线对齐,
"""
for i in range(1, 7):
# 以下用到的图片是在“代码中用到的图片”中的“images”文件夹中
img = cv2.imread(f"./images/0{i}.jpg")
# 抽取红色范围的二值图
img_rad = extract_rad_area(img)
# 获取轮廓并进行初步筛选
contours = find_filter_contours(img_rad)
# 画出来,同时获取各个轮廓的中心点坐标
result_img, centers, angles = draw_obtain(img, contours)
# 如果是一条完整的连续的线,也就一条;没错位但中间断开了,或者是错位了,就是两个轮廓;还有误判会可能不值2个框
if len(centers) > 1: # 现在的理想状态是>1, 其实就是2个轮廓的理想状态
# print("轮廓数目:", len(centers))
center_1, center_2 = centers
slope = (center_1[1] - center_2[1]) / (center_1[0] - center_2[0])
# slope为正,方向就是对的,因为原点在左上角,slope为负,
if slope >= 0:
center_angle = np.arctan(slope) * 180 / np.pi # 弧度转换为度
else:
center_angle = -np.arctan(abs(slope)) * 180 / np.pi
print(f"两个中心点之间连线形成的角度:{center_angle:.2f}°")
# 如果两个轮廓的角度相差过5° 或者 两轮廓中心点之间形成的角度和这个两个轮廓角度平均值偏离10°以上,则都认为防松动标记松了
if abs(angles[0] - angles[1]) > 5 or abs((angles[0] + angles[1])/2 - center_angle) > 10:
text = colored("防松动标记位置已经改变,请及时检查!", "red")
cv2.putText(result_img, "Error!", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
else:
text = colored("防松动标记位置正常!", "green")
cv2.putText(result_img, "Normal", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
print(text, "\n")
# cv2.imshow("original", img)
cv2.imshow(f"dst", result_img)
cv2.waitKey(0)
Tips:注意那个angle角度,特别就是这个demo,两个的角度几乎是平行的,如果直接是用rect[2]作为角度打印出来,是一个为90°左右,一个是2°左右,这不是我们想要的。
从opencv-4.5版本以后定义为:
==x轴顺时针==旋转最先重合的边为w,angle为x轴顺时针旋转的角度,angle取值为(0,90]。
所以当w>h时,得到的值就是我们要的;
当w<h时,这是就是以短边计算的角度了,我们还是希望以长边为计算角度以便统一,然后它就是从x轴的逆时针方向更快接触到长的一边,因为x轴逆时针,所以前面加个符号,值就是opencv算的角的补角,也就为-(90 - rect[2])
十、Hongh变换(霍夫)
●在图像处理中,霍夫变换用来检测任意能够用数学公式表达的形状,即使这个形状被破坏或者有点扭曲 ●使用Hough变换进行直线检测 ●了解Hough变换的原理
用的最多的是找圆找直线。自动驾驶也有关;那种早些时候,仓库里机器拿货,跟着画的线走,也是这原理。
10.1. 找直线
有两个API:(这百度的AI回答的区别,还没进行验证)
- cv2.HoughLinesP()方法专门用于检测线段,该方法最后把找出的所有线段的两个端点坐标保存成一个数组;
- cv2.HoughLines()方法是专门用于检测无限延长的直线,该方法要求所操作的源图像是一个二值图像,所检测的直线只有方向和距离两个参数,不能直接输出直线的端点坐标。
"""找直线"""
import numpy as np
image = cv2.imread("23.jpg")
image = cv2.GaussianBlur(image, (5, 5), 0)
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("image_gray", image_gray)
edges = cv2.Canny(image_gray, 100, 150) #Canny里面就有二值化
cv2.imshow("image_edges", edges)
lines = cv2.HoughLines(edges, 1, np.pi / 180, 100) #这是以极坐标来算的
#第二个参数代表ρ模长按照1来找,我这里用0.5似乎效果更好;再就是θ按照1°来算;再就两点间相隔超过100就算是2条线了
#这个函数就是霍夫变换,圆就是Lines换成Circles就好了
if lines is not None:
for line in lines:
rho, theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b)) # 直线起点横坐标
y1 = int(y0 + 1000 * (a)) # 直线起点纵坐标
x2 = int(x0 - 1000 * (-b)) # 直线终点横坐标
y2 = int(y0 - 1000 * (a)) # 直线终点纵坐标
cv2.line(image, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.imshow("image_lines", image)
cv2.waitKey(0)
-
下面是一个完整的示例:(一般还是用HoughLinesP)

import cv2 import numpy as np img = cv2.imread("pen.jpg") o = img.copy() # 复制原图 o = cv2.medianBlur(o, 5) # 使用中值滤波进行降噪 gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY) binary = cv2.Canny(o, 50, 150) # 检测直线,精度为1,全角度,阈值为15,线段最短100,最小间隔为18 lines = cv2.HoughLinesP(binary, 1, np.pi / 180, 15, minLineLength=100, maxLineGap=18) for line in lines: x1, y1, x2, y2 = line[0] # 读取直线两个端点的坐标 cv2.line(img, (x1, y1), (x2, y2), (0, 0, 255), 2) # 在原始图像上绘制直线 cv2.imshow("canny", binary) cv2.imshow("img", img) cv2.waitKey(0) -
然后opencv源码中的sample也不错:
''' Usage: houghlines.py [<image_name>] image argument defaults to pic1.png ''' import cv2 import numpy as np import sys import math def main(): try: fn = sys.argv[1] except IndexError: fn = 'pic1.png' # src = cv2.imread(cv.samples.findFile(fn)) src = cv2.imread(fn) dst = cv2.Canny(src, 50, 200) cdst = cv2.cvtColor(dst, cv.COLOR_GRAY2BGR) if True: # HoughLinesP lines = cv2.HoughLinesP(dst, 1, math.pi/180.0, 40, np.array([]), 50, 10) a, b, _c = lines.shape for i in range(a): cv2.line(cdst, (lines[i][0][0], lines[i][0][1]), (lines[i][0][2], lines[i][0][3]), (0, 0, 255), 3, cv2.LINE_AA) else: # HoughLines lines = cv2.HoughLines(dst, 1, math.pi/180.0, 50, np.array([]), 0, 0) if lines is not None: a, b, _c = lines.shape for i in range(a): rho = lines[i][0][0] theta = lines[i][0][1] a = math.cos(theta) b = math.sin(theta) x0, y0 = a*rho, b*rho pt1 = ( int(x0+1000*(-b)), int(y0+1000*(a)) ) pt2 = ( int(x0-1000*(-b)), int(y0-1000*(a)) ) cv2.line(cdst, pt1, pt2, (0, 0, 255), 3, cv2.LINE_AA) cv2.imshow("detected lines", cdst) cv2.imshow("source", src) cv2.waitKey(0) print('Done') if __name__ == '__main__': print(__doc__) main() cv.destroyAllWindows()
10.2. 找圆
"""找圆"""
image = cv2.imread("24.jpg")
dst = cv2.cvtColor(image, cv2.COLOR_BGRA2GRAY)
circle = cv2.HoughCircles(dst, cv2.HOUGH_GRADIENT, 1, 30, param1=40, param2=20, minRadius=20, maxRadius=300)
if circle is not None:
circle = np.uint16(np.around(circle))
for i in circle[0, :]:
cv2.circle(image, (i[0], i[1]), i[2], (0, 0, 255), 2)
cv2.imshow("circle", image)
cv2.waitKey(0)
-
下面是一个完整的示例:

import cv2 import numpy as np img = cv2.imread("coin.jpg") # 读取原图 o = img.copy() o = cv2.medianBlur(o, 5) # 使用中值滤波进行降噪 gray = cv2.cvtColor(o, cv2.COLOR_BGR2GRAY) # 检测圆环,圆心最小间距为70,Canny最大阈值为100,投票数超过25。最小半径为10,最大半径为50 circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1, 70, param1=100, param2=25, minRadius=10, maxRadius=50) circles = np.uint(np.around(circles)) # 将数组元素四舍五入成整数 for c in circles[0]: # 遍历圆环结果 x, y, r = c # 圆心横坐标、纵坐标和圆半径 cv2.circle(img, (x, y), r, (0, 0, 255), 3) # 绘制圆环 cv2.circle(img, (x, y), 2, (0, 0, 255), 3) # 绘制圆心 cv2.imshow("img", img) cv2.waitKey(0) -
以及opencv源码中的sample:
''' This example illustrates how to use cv2.HoughCircles() function. Usage: houghcircles.py [<image_name>] ''' import numpy as np import cv2 import sys def main(): try: fn = sys.argv[1] except IndexError: fn = 'board.jpg' # src = cv2.imread(cv2.samples.findFile(fn)) src = cv2.imread(fn) img = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) img = cv2.medianBlur(img, 5) cimg = src.copy() # numpy function circles = cv2.HoughCircles(img, cv2.HOUGH_GRADIENT, 1, 10, np.array([]), 100, 30, 1, 30) if circles is not None: # Check if circles have been found and only then iterate over these and add them to the image circles = np.uint16(np.around(circles)) _a, b, _c = circles.shape for i in range(b): cv2.circle(cimg, (circles[0][i][0], circles[0][i][1]), circles[0][i][2], (0, 0, 255), 3, cv2.LINE_AA) cv2.circle(cimg, (circles[0][i][0], circles[0][i][1]), 2, (0, 255, 0), 3, cv2.LINE_AA) # draw center of circle cv2.imshow("detected circles", cimg) cv2.imshow("source", src) cv2.waitKey(0) print('Done') if __name__ == '__main__': print(__doc__) main() cv2.destroyAllWindows()
10.3. 原理
霍夫变换就是将在一个形状上的点连起来;用直线来说说,那是怎么判断点在直线上的啊?根据直线公式 y = k*x + b,在一条直线上的点的k和b是一样的。
故霍夫变换是以 k 为x轴,固定一个x来遍历 k ,就会生成一条y关于k的直线,那么有多少个x就有多少条直线,那么直线的交点的x的 y 和 k 就是一样的,那么这些 x 点就是在一条线上的。
十一、图像分割(分水岭算法)
又称之为分水岭算法,用到的函数:cv2.watershed()
原理:
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水。随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝直到所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。这就是分水岭算法的背后哲理。 但是这种方法通常都会得到过度分割的结果,这是由噪声或者图像中其他不规律的因素造成的。为了减少这种影响,OpenCV 采用了基于掩模的分水岭算法,在这种算法中我要设置哪些山谷点会汇合,哪些不会。这是一种交互式的图像分割。我们要做的就是给我们已知的对象打上不同的标签。如果某个区域肯定是前景或对象,就使用某个颜色(或灰度值)标签标记它。如果某个区域肯定不是对象而是背景就使用另外一个颜色标签标记。而剩下的不能确定是前景还是背景的区域就用0标记。这就是我们的标签。然后实施分水岭算法。每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后我们得到的边界对象(堤坝)的值为-1。

如把这堆硬币切开,再OpenCV里,需要给它一点先验,也就是红色的那种提示。
img = cv2.imread('27.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
# noise removal # 开操作去掉背景里的噪声;中间的哪些空白如果大也有可能去掉噪
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# sure background area
sure_bg = cv2.dilate(opening, kernel, iterations=3) # 这个膨胀操作以后,所有的硬币就成了成了一饼,就可以获取背景了
dist_transform = cv2.distanceTransform(opening, 1, 5) # 距离变换
ret, sure_fg = cv2.threshold(dist_transform, 0.7 * dist_transform.max(), 255, 0) # 再阈值操作后,可以打出来看,就有了类似上面图上红点的那种先验
"""距离变换:假设有一个圆,把离边缘一小段的距离设为像素1,那么由边缘到中心的点的值就越来越大,
直观的反应就是由边缘到中心越来越亮。接下来再用阈值操作把不够亮的归零,中心位置弄成255,于是就有了上面说到的先验。"""
cv2.imshow("3", sure_fg) # 把这打印出来看,
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg, sure_fg) # 这就是用那一饼减去那类似先验的点;可以尝试把这几个打出来看看
# Marker labelling # 这几个看不懂啊,说是类似掩码,在做标记
ret, markers1 = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers1 + 1
# Now, mark the region of unknown with zero
markers[unknown == 255] = 0
markers3 = cv2.watershed(img, markers) # 在这之上都是在提供先验
img[markers3 == -1] = [0, 0, 255] # 这是找到了边缘在画红颜色
cv2.imwrite("54.jpg", img)
cv2.imshow("img", img)
cv2.waitKey(0)
十二、傅里叶变换(时域,频域转换)
12.1. 傅里叶变换
把时域空间问题转为频域空间的问题
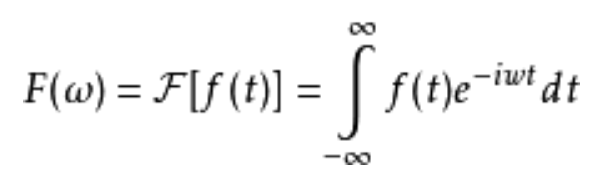
公式理解:f(t)理解为原图像;i是虚数单位;t是时间就代表图像上的位置,要么是x,要么是y
12.2. 傅里叶逆变换
把频域空间问题转为时域空间问题
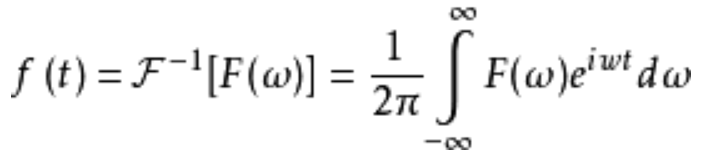
12.3. Numpy傅里叶变换
img = cv2.imread('13.jpg', 0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f) #这里是平移
magnitude_spectrum = 20 * np.log(np.abs(fshift)) #后面就是在求幅值,*20倍是放大好观察
plt.figure(figsize=(10, 10))
plt.subplot(2,2,1), plt.imshow(img, cmap='gray')
plt.title('Input Image'), plt.axis("off")
plt.subplot(2,2,2), plt.imshow(magnitude_spectrum, cmap='gray')
plt.title('Magnitude Spectrum'), plt.axis("off")
rows, cols = img.shape
crow, ccol = rows // 2, cols // 2
fshift[crow - 30:crow + 30, ccol - 30:ccol + 30] = 0
#上面三行就是做了一个窗口,然后中间置为0,相当于高通滤波,就提取轮廓
f_ishift = np.fft.ifftshift(fshift) #上面了平移了,这就要平移回去
img_back = np.fft.ifft2(f_ishift)
img_back = np.abs(img_back) #再是傅里叶逆变换得到图
plt.subplot(2,2,3), plt.imshow(img_back, cmap='gray')
plt.title('Image after HPF'), plt.axis("off")
plt.subplot(224), plt.imshow(img_back)
plt.title('Result in JET'), plt.xticks([]), plt.yticks([])
plt.show() #这个第三张图是提轮廓
上面列子的第二个图
分析:把原点0从左上角移到了最中间,中间越亮,说明靠近0的像素越多,那么就说明整幅图的低频信号较多。一般有在中间画个矩形框,将中间的信号置为0,那就是滤去了低频信号,保留了周围的高频信号,就找出轮廓;反之也可以·将矩形框外面的信号置为0,就是模糊图像,去噪。但是一般不用这种矩形框,是用高斯,不将其直接置为0,而是变得很小。
12.4. OpenCV傅里叶变换
img = cv2.imread('13.jpg', 0)
dft = cv2.dft(np.float32(img), flags=cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20 * np.log(cv2.magnitude(dft_shift[:, :, 0], dft_shift[:, :, 1])) #说是这里算幅值时,有虚部和实部,所以这样
plt.figure(figsize=(10, 10))
plt.subplot(221), plt.imshow(img, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(222), plt.imshow(magnitude_spectrum, cmap='gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
rows, cols = img.shape
crow, ccol = rows // 2, cols // 2
# create a mask first, center square is 1, remaining all zeros
mask = np.zeros((rows, cols, 2), np.uint8)
mask[crow - 30:crow + 30, ccol - 30:ccol + 30] = 1 #把整个图设为o,然后再把中间的设为1,就相当于低通滤波,就模糊了
fshift = dft_shift * mask #乘以掩码,这也是在滤波
# apply mask and inverse DFT
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift) #傅里叶逆变换回来
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1]) #因为有虚部,所以幅值不对,就要重新算回来
plt.subplot(223), plt.imshow(img_back, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(224), plt.imshow(img_back)
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show() #这个第三张图是模糊
十三、欧拉放大
欧拉放大分为颜色放大和动作放大,下面是颜色放大
宽:cap.get(cv2.CAP_PROP_FRAME_WIDTH)
高:cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
fps:cap.get(cv2.CAP_PROP_FPS)
总的帧数:cap.get(cv2.CAP_PROP_FRAME_COUNT)
更多的参数及意义看这里。
from scipy import fftpack
#scipy这个库跟numpy是姊妹库
# Build Gaussian Pyramid
def build_gaussian_pyramid(src, level=3):
s = src.copy()
pyramid = [s]
for i in range(level):
s = cv2.pyrDown(s)
pyramid.append(s)
return pyramid
# load video from file
# 获取基本参数:总的帧数、fps、宽高等基本属性 (=====注意这个======)
def load_video(video_filename):
cap = cv2.VideoCapture(video_filename)
# 总的帧数
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
width, height = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
video_tensor = np.zeros((frame_count, height, width, 3), dtype='float') #写进np里,(帧数,h,w,c)
x = 0
while cap.isOpened():
ret, frame = cap.read()
if ret is True:
video_tensor[x] = frame
x += 1
else:
break
return video_tensor, fps
# apply temporal ideal bandpass filter to gaussian video
def temporal_ideal_filter(tensor, low, high, fps, axis=0):
fft = fftpack.fft(tensor, axis=axis) #这里是在做傅里叶变换;如果是用numpy或opencv,就要写循环,因为他俩只能对单张图片操作,不能操作张量
#axis给的维度是0,就是说每一张都要做变换
frequencies = fftpack.fftfreq(tensor.shape[0], d=1.0 / fps) #这句就是在移动到中间来,要对称,不然后面傅里叶逆变换就要报错
bound_low = (np.abs(frequencies - low)).argmin()
bound_high = (np.abs(frequencies - high)).argmin()
fft[:bound_low] = 0
fft[bound_high:-bound_high] = 0
fft[-bound_low:] = 0 #上面就在滤波了,,看不懂时,自己写个小例子去到底滤的哪部分
iff = fftpack.ifft(fft, axis=axis) #再傅里叶逆变换回来
return np.abs(iff)
# build gaussian pyramid for video
def gaussian_video(video_tensor, levels=3):
for i in range(0, video_tensor.shape[0]):
frame = video_tensor[i]
pyr = build_gaussian_pyramid(frame, level=levels)
gaussian_frame = pyr[-1]
if i == 0:
vid_data = np.zeros((video_tensor.shape[0], gaussian_frame.shape[0], gaussian_frame.shape[1], 3))
vid_data[i] = gaussian_frame
return vid_data
# amplify the video
def amplify_video(gaussian_vid, amplification=50):
return gaussian_vid * amplification
# reconstract video from original video and gaussian video
def reconstract_video(amp_video, origin_video, levels=3):
final_video = np.zeros(origin_video.shape)
for i in range(0, amp_video.shape[0]):
img = amp_video[i]
for x in range(levels):
img = cv2.pyrUp(img)
img = img + origin_video[i]
final_video[i] = img
return final_video
# save video to files
def save_video(video_tensor):
fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
[height, width] = video_tensor[0].shape[0:2]
writer = cv2.VideoWriter("out.avi", fourcc, 30, (width, height), 1)
for i in range(0, video_tensor.shape[0]):
writer.write(cv2.convertScaleAbs(video_tensor[i]))
writer.release()
# magnify color
def magnify_color(video_name, low, high, levels=3, amplification=20):
#呼吸是在中间频率,所以设置一个上下区间段,中间有缩放,所以是0.4,3,金字塔层数;放大的倍数
t, f = load_video(video_name) #加载视频,load_video()函数是自己写的
gau_video = gaussian_video(t, levels=levels) #高斯视频金字塔,每一帧都做高斯金字塔,在合起来
filtered_tensor = temporal_ideal_filter(gau_video, low, high, f) #中通滤波
amplified_video = amplify_video(filtered_tensor, amplification=amplification) #放大
final = reconstract_video(amplified_video, t, levels=3) #融合重构
save_video(final)
if __name__ == "__main__":
magnify_color("baby.mp4", 0.4, 3)
就是放大婴儿呼吸那个。
十四、特征提取
14.1. xfeatures2d错误
由于专利的问题surf和sift特征已经被移到xfeatures2d里面,这个模块需要安装opencv-contrib-python
opencv的dnn模块可以加载深度学习模型,但是dnn需要3.4以上,但是4.0以上的opencv-python和opencv-contrib-python更加找不到xfeatures2d。
所以如果需要用到以上两个,既要DNN又需要xfeatures2d的话,那就需要找到一个更加合适的版本
pip install opencv-python==3.4.2.17
pip install opencv-contrib-python==3.4.2.17 # == 这符号左右不要空格
就能满足上述需求,注意安装顺序,需要先按照opencv-python,然后安装opencv-contrib-python
pip install opencv-python是安装最新版本,卸载就是pip uninstall opencv-python
14.2. Harris==角点==检测
- 理解Harris角点检测的概念
- 学习函数: cv2.cornerHarris(), cv2.cornerSubPix()
- 数学原理(不要求完全掌握)
img = cv2.imread("29.jpg") #28.jpg也是用在这里的
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04) #2矩形size;3核大小;0.04阈值大小
dst = cv2.dilate(dst, cv2.getStructuringElement(cv2.MORPH_RECT, (8, 8)))
#这是一个膨胀操作,使标出来的红点更加明显,可以试着先去掉对比一下
img[dst > 0.01 * dst.max()] = [0, 0, 255] #发现是角点的标注成红颜色
cv2.imshow('dst', img)
cv2.waitKey(0)
14.3. 亚像素级精确度的角点
最小像素是1,也会存在0.2这种像素位置,就是亚像素。
有时我们需要最大精度的角点检测。OpenCV为我们提供了函数cv2.cornerSubPix(),它可以提供亚像素级别的角点检测。下面是一个例子。 首先我们要找到Harris角点,然后将角点的重心传给这个函数进行修正。Harris 角点用红色像素标出,绿色像素是修正后的像素。在使用这个函数是我们要定义一个迭代停止条件。当迭代次数达到或者精度条件满足后迭代就会停止。我们同样需要定义进行角点搜索的邻域大小。(代码不贴了,书签里opencv中文档有,第30个知识点)
14.4. SIFT
(Scale-Invariant Feature Trans-form);精度可以,但是算的有点慢。有只是产权专利的,,要注意,专利已经到期,看官方解释,已经将其移进主仓库了,可直接使用。
img = cv2.imread('4.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# sift = cv2.cv2.xfeatures2d.SIFT_create()
sift = cv2.SIFT_create() # 可直接使用,不再要opencv_contrib
kp = sift.detect(gray, None)
img = cv2.drawKeypoints(img, kp, None, color=(0, 0, 255)) #注意画点时,这里要给个None
cv2.imshow('img', img)
cv2.waitKey(0)
14.5. 介绍SURF
(Speeded-Up Robust Feature),上一个方法的改进。
sift = cv2.xfeatures2d.SURF_create() #跟上就这一行不同
14.6. 简单掌握角点检测的FAST算法
因为突出快,更常用于机器人视野领域
- FAST算法是一-种更快的算法
- FAST算法的思想是,若某像素与其周围邻域内足够多的像素点相差较大,则该像素可能是角点
- 在筛选出来的候选角点中有很多是紧挨在一 起的,需要通过非极大值抑制来消除这种影响
- 缺陷:
- 当n<12时可能会有较多的候选角点出现
- 过度依赖于阈值 (主要就跟多大范围比较;相差较大是多大;这俩阈值)
src = cv2.imread("30.jpg")
grayImg = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
fast = cv2.FastFeatureDetector_create(threshold=35) #这里就是设置阈值
kp = fast.detect(grayImg, None)
img2 = cv2.drawKeypoints(src, kp, None, (0, 0, 255), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
print('Threshold: ', fast.getThreshold())
print('nonmaxSuppression: ', fast.getNonmaxSuppression())
print('neighborhood: ', fast.getType())
print('Total Keypoints with nonmaxSuppression: ', len(kp))
cv2.imshow('fast_true', img2) #这里是做了非极大值抑制的图
fast.setNonmaxSuppression(False) #这行填True就是代表做非极大值抑制;可以不要看看区别
kp = fast.detect(grayImg, None)
print('Total Keypoints without nonmaxSuppression: ', len(kp))
img3 = cv2.drawKeypoints(src, kp, None, (0, 0, 255), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('fast_false', img3)
cv2.waitKey()
说明:为啥要用非极大值抑制?
因为一个点跟周围一些点的差别很大,那么那些点反过来跟这个点跟他周围的点差别可能也会很大,那么一个区域内,就会重叠很多,就要用非极大值抑制来尽可能减少一个区域内重叠的点。
14.7BRIEF
Binary Robust Independent Elementary Features
●一种对已检测到的特征点进行描述的算法,它是一 种二进制编码的描述子,在图像匹配时使用BRIEF能极大的提升匹配速度。
海明距离
现在也叫汉明距离 hanming
简单来说,把每个点的数据全部变成0和1,在进行 “海明距离” 运算,就是两个点的对应位置进行异或运算,然后再把1个个数出来就是海明距离。
14.8. ORB算法(用这)
“注意啊,我们都是用这个算法!”
(Oriented FAST and Rotated BRIEF)
- ORB是FAST与BRIEF合体
- ORB没有专利,SIFT和SURF是有专利的
img = cv2.imread("30.jpg")
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
orb = cv2.ORB_create()
kp = orb.detect(grayImg, None)
kp, des = orb.compute(grayImg, kp)
img2 = cv2.drawKeypoints(img, kp, None, color=(0, 0, 255), flags=0)
cv2.imshow("img", img2)
cv2.waitKey(0)
(2012-12-31opencv03)这个文件夹里第二个视频的最后那里;说这个上面代码没有做什么NS,听不清楚,后面要注意啊。
十五、特征匹配
学了上面的特征提取,就是为了特征匹配。
15.1. Brute-Force
●蛮力匹配器首先在第一幅图像中选取一-个关键点然后依次与第二幅图像的每个关键点进行(描述符)距离测试,最后返回距离最近的关键点。 ●matches = bf.match(des1,des2)返回值是一一个DMatch对象列表。这个DMatch 对象具有下列属性:
●DMatch.distance -描述符之间的距离。越小越好。 ●DMatch.trainldx -目标图像中描述符的索引。 ●DMatch.queryldx -查询图像中描述符的索弓|。 ●DMatch.imgldx-目标图像的索引。
import cv2
img1 = cv2.imread('31.jpg')
grayImg1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('30.jpg')
grayImg2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(grayImg1, None)
kp2, des2 = orb.detectAndCompute(grayImg2, None) #先用ORB算法把特征点找出来
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True) #再用蛮力匹配
#括号里的第一个参数表示用的海明距离,也可以是其他距离,但是海明距离最快
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance) #排序,距离最短的排序
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:20], None, flags=2)
#这的[:20]代表画的点的个数,前面排了序,画最短的20个
cv2.imshow("img",img3)
cv2.waitKey(0) #效果还行,就是较慢
15.2. FLANN匹配器
FLANN是快速最近邻搜索包(Fast_ Library_ for_ Approximate_ Nearest_ Neighbors) 的简称。它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集时它的效果要好于BFMatcher。 我们来对第二个例子使用FL ANN匹配看看它的效果。 使用FLANN匹配,我们需要传入两个字典作为参数。这两个用来确定要使用的算法和其他相关参数等。第一个是IndexParams。各种不同算法的信息可以在FLANN文档中找到。这里我们总结一下,对于SIFT和SURF等,我们可以传入的参数是:
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
还可以使用ORB,具体的在opencv中文教程里,然后其书签在浏览器里。
img1 = cv2.imread('31.jpg')
grayImg1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('30.jpg')
grayImg2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create() #就是那个SIFT算法
kp1, des1 = sift.detectAndCompute(grayImg1, None)
kp2, des2 = sift.detectAndCompute(grayImg2, None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2) #这里就是那个KNN
matchesMask = [[0, 0] for i in range(len(matches))]
for i, (m, n) in enumerate(matches):
if m.distance < 0.7 * n.distance:
matchesMask[i] = [1, 0]
draw_params = dict(matchColor=(0, 255, 0),
singlePointColor=(255, 0, 0),
matchesMask=matchesMask,
flags=0)
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **draw_params)
cv2.imshow("img", img3)
cv2.waitKey(0)
15.3. 特征匹配和单映射查找对象
就把那个对象猪框起来
import cv2
import numpy as np
MIN_MATCH_COUNT = 10
img1 = cv2.imread('31.jpg') # 也可以用彩图
grayImg1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('30.jpg')
grayImg2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# Initiate SIFT detector
# sift = cv2.cv2.xfeatures2d.SIFT_create()
sift = cv2.SIFT_create() # 已岛主仓库,可直接使用,不再要opencv_contrib
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(grayImg1, None) # 这是要匹配的小图
kp2, des2 = sift.detectAndCompute(grayImg2, None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) > MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0) #主要就这函数
matchesMask = mask.ravel().tolist()
h, w = grayImg1.shape
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
dst = cv2.perspectiveTransform(pts, M) #说是透视变换
img2 = cv2.polylines(img2, [np.int32(dst)], True, 255, 3, cv2.LINE_AA)
else:
print("Not enough matches are found - %d/%d" % (len(good), MIN_MATCH_COUNT))
matchesMask = None
# Finally we draw our inliers (if successfully found the object) or matching keypoints (if failed).
draw_params = dict(matchColor=(0, 255, 0), # draw matches in green color
singlePointColor=None,
matchesMask=matchesMask, # draw only inliers
flags=2)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, good, None,**draw_params)
cv2.imshow("img", img3)
cv2.waitKey(0)
注意:以上的代码不求全懂,,拿来直接用,效果不佳时,再去琢磨参数的调节修改
十六、视频处理
详细都去看那个opencv中文文档,书签里都有
16.0 突然断开后的重连
-
写前面,注意,==不要在视频流取画面中加time.sleep()==,会导致流断开,然而cap.isOpend()返回的结果还是True,cap.read()的返回结果也还是错,其实已经有问题了(这是用安全帽时发现的问题,因为加了延时,可以在srs流媒体端发现,大概几十秒,这拉流就断开了,然而21、22行代码还在打印True)
import cv2 import time from datetime import datetime rtsp_path = r"rtmp://192.168.108.218/live/34" cap = cv2.VideoCapture() cap.open(rtsp_path) stream_flag = False while True: success, frame = cap.read() if success: print(frame[0, 1, 1]) stream_flag = True else: stream_flag = False cap.open(rtsp_path) time.sleep(20) # 前面不要在这里面加 这种 延时语句 print(f"流状态: {stream_flag}") print(f"打开了? {cap.isOpened()}")
这是在yolov5中对流媒体操作中学到的:(也有跳帧处理的实行),多线程方式
import cv2
import time
from datetime import datetime
from queue import Queue
import threading
from threading import Thread
g_Exit = False
def get_timestamp(only_time=False):
now_time = datetime.now()
if only_time:
return now_time.strftime("%H:%M:%S")
return now_time.strftime("%Y-%m-%d %H:%M:%S")
def image_put(source, q: Queue, video_stride=15):
cap = cv2.VideoCapture(source)
assert cap.isOpened(), "Failed to open the video stream!"
w = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
h = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
fps = cap.get(cv2.CAP_PROP_FPS)
print(w, h, fps)
n = 0
while True:
n += 1
# 这一步在相机断开后,会在这卡一段时间
success = cap.grab() # .read() = .grab() followed by .retrieve()
if not success:
while True:
ret = cap.open(source)
if ret:
break
else:
print("{}, 摄像头读取失败,30秒后再次尝试...".format(get_timestamp()))
time.sleep(30)
continue
if n % video_stride != 0: # 每多少帧取一次
continue
success, frame = cap.retrieve()
print("结果:", success)
if not success:
while True:
ret = cap.open(source)
if ret:
break
else:
print("{}, 摄像头读取失败,30秒后再次尝试...".format(get_timestamp()))
time.sleep(30)
continue
print(frame.shape)
if q.full():
q.get_nowait()
q.put_nowait(frame)
if g_Exit:
break
cap.release()
if __name__ == '__main__':
rtsp_path = r"rtsp://192.168.108.132:554/user=admin&password=&channel=1&stream=0.sdp?"
que = Queue(maxsize=2)
t1 = Thread(target=image_put, args=(rtsp_path, que), daemon=True)
t1.start()
time.sleep(1)
while True:
frame = que.get()
string = get_timestamp(only_time=True)
cv2.putText(frame, string, (500, 700), cv2.FONT_HERSHEY_PLAIN, 2, (0, 0, 255), 2, cv2.LINE_AA)
cv2.imshow("mul", frame)
if cv2.waitKey(1) & 0xFF != 255:
g_Exit = True
break
t1.join()
cv2.destroyAllWindows()
16.1. 摄像头操作
cap = cv2.VideoCapture(0) #0代表调用电脑上第一个摄像头,
# cap = cv2.VideoCaptyre("12.mp4") #也可以是视频绝对地址;设置成cv2.waitKey(25)毫秒较好
# while True: #固定要用
while cap.isOpened():
ret, frame = cap.read()
#_, frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #这种就是可以对每帧图片进行操作,这里是转灰度,主要是针对读取视频文件时
cv2.imshow('frame', frame)
key = cv2.waitKey(1) & 0xFF
if key == 32: # 按空格暂停(32就是空格)
cv2.waitKey(0) # 暂停后按任意键继续运行(在这种时,按下任意键他就会往后)
# if waitKey(24) & 0xFF != 255: # 这也是按任意键
elif key == 27: # 正常运行状态下,按下esc退出程序(27就是esc)
break
elif key == ord('q'): #(0)就会卡主, 后面部分代表监听键盘,若是输入q就执行下面代码
# 其实会发现后面的0xFF其实没多少意义,主要还是看前面,原因是 waitkey() 如果不按键的时候是返回 oxff,oxff无符号时是255,有符号时是-1。windows vs 的环境默认了这个为非符号数 即255,而opencv的有些配置环境中是-1。
cap.release() #释放掉摄像头
cv2.destroyAllWindows() #释放掉窗口
还可以放类似这样的视频流地址,就可以看电视台直播http://ivi.bupt.edu.cn/hls/cctv1hd.m3u8
16.2. 读写,编辑视频
注意:在读取摄像头时,默认分辨率是640×480,如果改变了分辨率,设备是正常运行的(前提是摄像头硬件得支持),但是把frame数据打出来看全是0了,这样子也能正常写成视频,视频的播放也没问题,但是如果要做后续的处理是不行的,这样子的视频,读取出来的帧的值也全是0.
可以配合MTCNN进行视频人脸侦测
if __name__ == '__main__':
video_path = r"G:/123.mp4"
fourcc = cv2.VideoWriter_fourcc(*'XVID') #给格式,前面是一个乘号
out = cv2.VideoWriter("output.avi", fourcc, 20.0, (640, 480), 1) #20.0是fps;最后的1代表每一帧是彩色图(默认为True),否则就是灰度图
cap = cv2.VideoCapture(video_path)
detector = Detector() #这是MTCNN的侦测类(自己写的代码)
frameNum = 0
while True:
ret, frame = cap.read() #注意opencv读进来的图片是BGR格式,要转成RGB才能在其他地方用
frameNum += 1
if frameNum %1 == 0:
data = frame[..., ::-1] #必须这样,这里只是换数据位置,不是换轴,形状没变,不能用下面的transpose
# data = np.array(frame).transpose((2, 1, 0))
image = Image.fromarray(data.astype("uint8"), "RGB")
boxes = detector.detect(image)
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
cv2.rectangle(frame, (x1, y1), (x2, y2), color = (0, 255, 255), thickness = 2)
# cv2.imshow("frame", frame)
out.write(frame) #写入视频
if cv2.waitKey(1) & 0XFF == ord("q"):
break
cap.release()
out.release()
cv2.destroyAllWindows()
cv2.imwrite('image/output/vieo1_' + str(frameNum) + ".jpg", frame) # 保存图片
cv2.namedWindow("resized", 0) # 0可以改变窗口大小了
# cv2.resizeWindow("resized", 640, 480) # 设置固定大小不能该,上面和一起使用
==写视频的参数==
fourcc = cv2.VideoWriter_fourcc(*'XVID') #给格式,前面是一个乘号
# 现在写入好像格式只能给`.avi`,其它的都不行
out = cv2.VideoWriter("oupput.avi", fourcc, 20.0, (640, 480), 1) #20.0是fps;最后的1代表每一帧是彩色图(默认为True),否则就是灰度图
FourCC 就是一个 4 字节码,用来确定视频的编码格式。可用的编码列表可以从fourcc.org查到。这是平台依赖的,下面对这些编码器的一个说明:
- In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID is more preferable. MJPG results in high size video. X264 givesvery small size video)
- In Windows: DIVX (More to be tested and added)
- In OSX : (I don’t have access to OSX. Can some one fill this?)
两种方式传递格式:
- fourcc = cv2.VideoWriter_fourcc(*‘MJPG’)
- fourcc = cv2.VideoWriter_fourcc(‘M’,’J’,’P’,’G’)
Ps:
MJPG这个格式比XVID大很多,它的数据速率和总比特率会大很多
可以点击这里找到FOURCC代码列表
一个奇怪的点:暂时算是bug吧,不知道为什么,
"""
一个问题:
opencv把图片存为视频,真有点奇怪啊,它最后保存的是视频总帧数始终只有图片数量的一半,无论保存图片时fps设置为多少;
即:(不懂为什么,后续用到这个功能是,注意一下)
1000张图,fps设为20,视频结果总帧数500,时长是500/20;
1000张图,fps设为40,视频结果总帧数500,时长是500/40;
800张图,fps设为20,视频结果总帧数400,时长是400/20;
"""
改变窗口大小
其它比如获取fps、视频宽高等参数看十三、欧拉放大的代码里。
cv2.namedWindow("frame", 0) # 0可调大小(就是成成的窗口是可以手动拖动大小,放1的话就不行),注意:窗口名必须imshow里面的一窗口名一样
cv2.resizeWindow("frame", 1600, 900) # 设置窗口的长和宽
cv2.moveWindow("frame", 100, 100) # 这就是把窗口开启位置最上角定位(100, 100)
while True:
ret, frame = cap.read()
# 调整窗口大小
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Tips:
- 在python下,要先设置
namedWindow,后面两个能生效,但是还对窗口位置的移动,大小缩放的拖拽都是可以; - 在c++下,namedWindow(“frame”, 0),就可以改变窗口大小及拖动窗口(但是图可能一开始显示不全),只要设定了resizeWindow,窗口大小拖拽就不让改了,设定了moveWindow,位置也就固定了,也不让拖拽移动了。 但一开始若给的namedWindow(“frame”, 1),也就是用的1,那一开始的图一定是显示完全的,但是就不让拖拽缩放了(linux下这样,vs应该是可以拖拽但不让缩放了)
16.3. Meanshift
视频是由图片每帧组合起来的,要在视频中追踪某个物体,那主要就是看轨迹变化;一开始有一个框,然后朝着变化最多的方向去动(一般动的物体的轨迹上变化是最多的),然后就实现的追踪。
cap = cv2.VideoCapture('car.mp4')
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# Draw it on image
x,y,w,h = track_window
img2 = cv2.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv2.imshow('img2',img2)
k = cv2.waitKey(60)
else:
break
cv2.destroyAllWindows()
cap.release() #一开始初始化没弄好,所以一开始有点没框好
16.4. Camshift
对上一个方法的改进,上一个方法的框是不变的,,这个大概是根据获得的框去自适应变化其形状和方向,形状大抵是获得其外切圆。
import cv2
import numpy as np
cap = cv2.VideoCapture('car.mp4')
# take first frame of the video
ret, frame = cap.read()
# setup initial location of window
r, h, c, w = 250, 90, 400, 125 # simply hardcoded the values
track_window = (c, r, w, h)
#300 190 390 210
# set up the ROI for tracking
roi = frame[r:r + h, c:c + w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60., 32.)), np.array((180., 255., 255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
while (1):
ret, frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# apply meanshift to get the new location
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# Draw it on image
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame, [pts], True, 255, 2)
cv2.imshow('img2', img2)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k) + ".jpg", img2)
else:
break
cv2.destroyAllWindows()
cap.release() #因为视频有些不一样,一开始没框好,后面可以尝试去改改
16.5. 光流
具体也是看文档。
简单来说,也是根据目标移动,来追踪目标。就是如果目标不动就识别不了了。
cap = cv2.VideoCapture('car.mp4')
# params for ShiTomasi corner detection
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7)
# Parameters for lucas kanade optical flow
lk_params = dict(winSize=(15, 15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# Create some random colors
color = np.random.randint(0, 255, (100, 3))
# Take first frame and find corners in it
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# Create a mask image for drawing purposes
mask = np.zeros_like(old_frame)
while (1):
ret, frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# calculate optical flow
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# Select good points
good_new = p1[st == 1]
good_old = p0[st == 1]
# draw the tracks
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv2.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('frame', img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# Now update the previous frame and previous points
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv2.destroyAllWindows()
cap.release()
视频移动框选跟踪
class MessageItem(object):
# 用于封装信息的类,包含图片和其他信息
def __init__(self, frame, message):
self._frame = frame
self._message = message
def getFrame(self):
# 图片信息
return self._frame
def getMessage(self):
# 文字信息,json格式
return self._message
class Tracker(object):
'''
追踪者模块,用于追踪指定目标
'''
def __init__(self, tracker_type="BOOSTING", draw_coord=True):
'''
初始化追踪器种类
'''
# 获得opencv版本
(major_ver, minor_ver, subminor_ver) = (cv2.__version__).split('.')
self.tracker_types = ['BOOSTING', 'MIL', 'KCF', 'TLD', 'MEDIANFLOW', 'GOTURN']
self.tracker_type = tracker_type
self.isWorking = False
self.draw_coord = draw_coord
# 构造追踪器
if int(minor_ver) < 3:
self.tracker = cv2.Tracker_create(tracker_type)
else:
if tracker_type == 'BOOSTING':
self.tracker = cv2.TrackerBoosting_create()
if tracker_type == 'MIL':
self.tracker = cv2.TrackerMIL_create()
if tracker_type == 'KCF':
self.tracker = cv2.TrackerKCF_create()
if tracker_type == 'TLD':
self.tracker = cv2.TrackerTLD_create()
if tracker_type == 'MEDIANFLOW':
self.tracker = cv2.TrackerMedianFlow_create()
if tracker_type == 'GOTURN':
self.tracker = cv2.TrackerGOTURN_create()
def initWorking(self, frame, box):
'''
追踪器工作初始化
frame:初始化追踪画面
box:追踪的区域
'''
if not self.tracker:
raise Exception("追踪器未初始化")
status = self.tracker.init(frame, box)
if not status:
raise Exception("追踪器工作初始化失败")
self.coord = box
self.isWorking = True
def track(self, frame):
'''
开启追踪
'''
message = None
if self.isWorking:
status, self.coord = self.tracker.update(frame)
if status:
message = {"coord": [((int(self.coord[0]), int(self.coord[1])),
(int(self.coord[0] + self.coord[2]), int(self.coord[1] + self.coord[3])))]}
if self.draw_coord:
p1 = (int(self.coord[0]), int(self.coord[1]))
p2 = (int(self.coord[0] + self.coord[2]), int(self.coord[1] + self.coord[3]))
cv2.rectangle(frame, p1, p2, (255, 0, 0), 2, 1)
message['msg'] = "is tracking"
return MessageItem(frame, message)
if __name__ == '__main__':
# 初始化视频捕获设备
gVideoDevice = cv2.VideoCapture("car.mp4")
gCapStatus, gFrame = gVideoDevice.read()
# 选择 框选帧
print("按 n 选择下一帧,按 y 选取当前帧") #这行感觉没用
while True:
if (gCapStatus == False):
print("捕获帧失败")
quit()
# _key = cv2.waitKey(0) & 0xFF
_key = 121 #因为不知道上面那行的意义;0xFF是255的16进制,这里直接令的,因为ord("y")=121
if (_key == ord('n')):
gCapStatus, gFrame = gVideoDevice.read()
if (_key == ord('y')):
break
cv2.imshow("pick frame", gFrame) #这个窗口出来后,,在上面画框,然后回车
# 框选感兴趣区域region of interest
cv2.destroyWindow("pick frame")
gROI = cv2.selectROI("ROI frame", gFrame, False)
if (not gROI):
print("空框选,退出")
quit()
# 初始化追踪器
gTracker = Tracker(tracker_type="KCF")
gTracker.initWorking(gFrame, gROI)
# 循环帧读取,开始跟踪
while True:
gCapStatus, gFrame = gVideoDevice.read()
if (gCapStatus):
# 展示跟踪图片
_item = gTracker.track(gFrame)
cv2.imshow("track result", _item.getFrame())
if _item.getMessage():
# 打印跟踪数据
print(_item.getMessage())
else:
# 丢失,重新用初始ROI初始
print("丢失,重新使用初始ROI开始")
gTracker = Tracker(tracker_type="KCF")
gTracker.initWorking(gFrame, gROI)
_key = cv2.waitKey(1) & 0xFF
if (_key == ord('q')) | (_key == 27):
break
if (_key == ord('r')):
# 用户请求用初始ROI
print("用户请求用初始ROI")
gTracker = Tracker(tracker_type="KCF")
gTracker.initWorking(gFrame, gROI)
else:
print("捕获帧失败")
quit()
受电弓摄像头地址参数介绍
发现:usb摄像头处理不过来时就会丢弃,画面虽然卡顿,但是比较实时,而rtsp摄像头,当处理不过来时,数据就会一支堆积,画面就一直很滞后,后续考虑用队列来操作吧,处理不了的数据直接丢弃。
# path= "rtsp://admin:yunda@12345@192.168.108.175:554"
# path = r"rtsp://admin:@192.168.108.175:554" # 用户名密码都无所谓;这三个效果都是一样的
# path = r"rtsp://admin:@192.168.108.175" # 前面有了rtsp,默认端口号就是554,也就可以不用给了(然后像这种r"rtsp://admin:@192.168.108.175/stream" 后面跟的 /stream 或是其它什么都没意义,跟与不跟一点影响没有,)
path = r"rtsp://192.168.108.175:554/user=admin&password=&channel=1&stream=1.sdp?" # tream=0是主码率;stream=1是副码率
cap = cv2.VideoCapture(path)
print(cap.isOpened())
print("fps:", int(cap.get(cv2.CAP_PROP_FPS)))
print(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
while cap.isOpened():
ret, frame = cap.read()
print(frame.shape)
if not ret:
break
cv2.imshow("1", frame)
if cv2.waitKey(1) & 0xFF != 255:
break
"""
受电弓摄像头视频流格式:
rtsp://192.168.1.10:554/user=admin&password=&channel=1&stream=0.sdp?
192.168.1.10这个是被连接的设备的IP
:554这个是RTSP服务的端口号,可以在设备的网络服务里面更改
user=admin这个是设备的登录用户名
password= 密码空
channel=1 第一通道
stream=0.sdp?主码流
stream=1.sdp?副码流
"""
海康摄像头说明
海康有两种方式:海康默认账号admin,默认密码123456,遇到海康摄像头的都可以这样试下。网上买的常用的摄像头,密码很可能为空。
- 仅主码流(跟其它相机一样):rtsp://admin:123456@192.168.108.81 # :554端口可以不要,这直接就是主码流.
- 第二种:
- 主码流:rtsp://admin:123456@192.168.108.81:554/ch1/main/av_stream
- 副码流:rtsp://admin:123456@192.168.108.81:554/ch1/sub/av_stream
十七、LearnOpenCV
这个项目里包含了很多我们可能会用到的小方法。
- EpipolarGeometryAndStereoVision:带深度检测的目标检测。(看网址中的博客)
- Exploring-Slicing-Aided-Hyper-Inference:yolov8带SAHI,专注小目标检测。
- Anchor Free Object Detection:
- 人脸相关的(人脸检测、换脸、融合、关键点,表情等等),直接去这个项目上搜索 face(或者 facial)
- Fine-Tuning-yolov7:从这里面看一下微调的方法。
- 了解一下opencv的cuda使用demo。还有dnn模块。
- Hand Keypoint Detection:手的关键点
- HeadPose:Head Pose Estimation using OpenCV and Dlib
- Homography:位置变换后,仍然能对应相同的点位

- 动作识别:使用Detectron2 and LSTM
- Object Keypoint Similarity:通过关键点判断动作的相似度。
- Multi Person Pose:多人动作识别,openpose。
- 不良姿势识别。地址。
- 视频分类,动作预测,地址。
- AI健身教练分析深蹲,拓展到其它运动,地址。
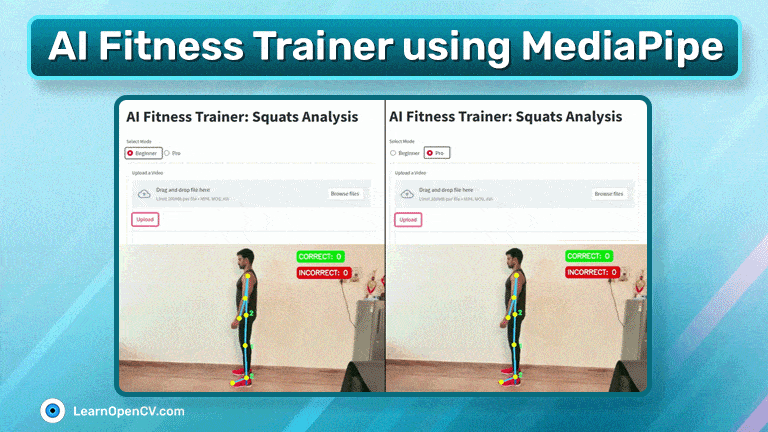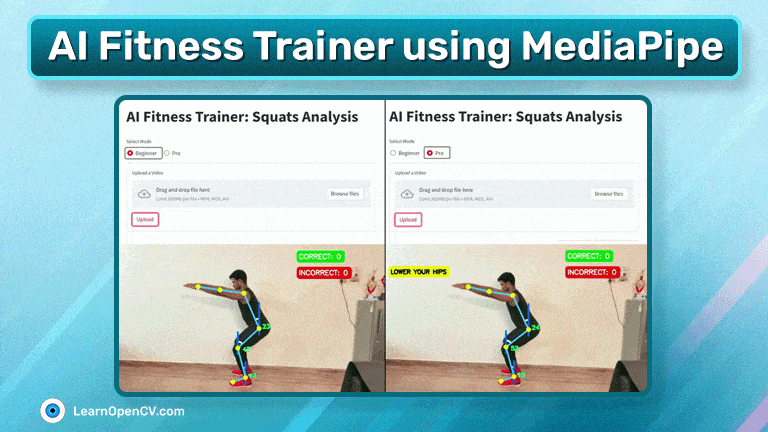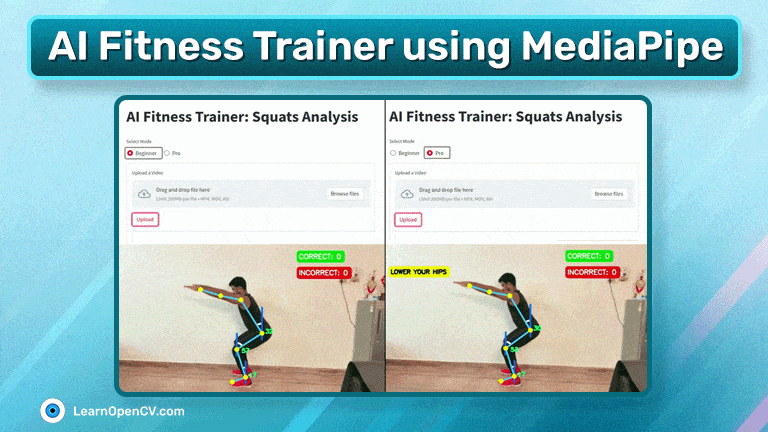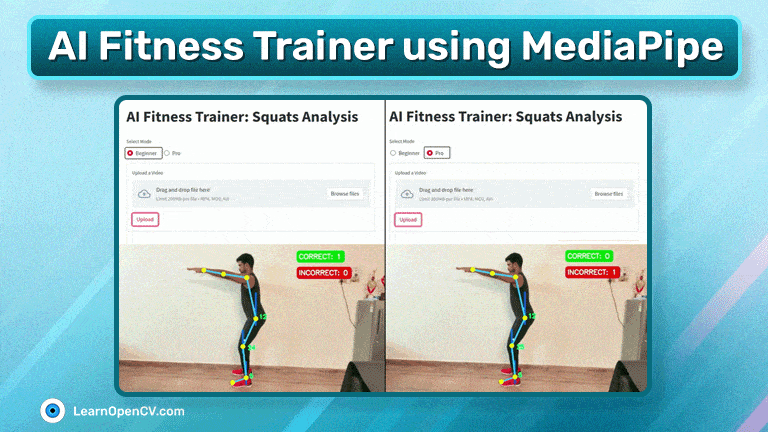
- 重要:ImageAlignment:根据特征把图摆正。

- Image Quality Assessment:图片质量评估。
- 所搜 Introduction 开头,会介绍一下,mediapipe、openVino之类的。
- MultiObjectTracker:多目标追踪。
- Object Tracking and Reidentification with FairMOT:目标追踪和重识别
- Real_Time_Deep_SORT:实时目标追踪。
- Understanding Multiple Object Tracking using DeepSORT:地址。
- 塑料垃圾检测。
- QR Code:二维码扫描,WeChat QR Code。二维码及条形码。
- 去除视频背景。地址; 还有这个。
- heatmap,做一个关键点检测可以参考。
- qt和opencv:地址。
- 自动车牌识别,里面还有deepSort-tracker

- Delaunay:三角化,三维重建中常用,以及泊松三角化。
- UnderstandingLensDistortion:理解镜头畸变。
最终opencv里自带的sample也是不错,python的示例看到了 “mouse_and_match.py”,我是从下往上看的。
十八、二维码扫描解析
微信扫描效果非常好,微信也贡献给了opencv,为了容错,还加了pyzbar,一起使用,使用方法如下:
环境准备:
- 安装opencv-contrib-python包(pip install opencv-contrib-python),注意安装的包不能低于4.5.2版本,下面方式一才能使用。
- 对应模型下载地址。本地也下好了,在此文件路径下的“./代码中用到的图片/model/”文件夹中。
- 安装pyzbar,win直接pip安装; 如果是用在ubuntu的话,需要先安装“apt-get install libzbar-dev”。 centos的话,先安装“yum install zbar-devel”。然后再pip安装包。
后续读不出来的进阶尝试:
- 二维码的识别一定要摆正,效果最好。所以,如果各种方式都读不来出,可以尝试将图片旋转90°、180°、270°以及45°、135°等都去试试,尽可能将二维码识别出来。
- c++的二维码识别库:Quirc是一个基于C/C++的一个二维码库,还没试过,有需要来看这。
import cv2
from pyzbar import pyzbar
def pyzbarQRCode(img):
result = ""
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
info = pyzbar.decode(img_gray)
if info:
result = info[0].data.decode()
return result
if __name__ == "__main__":
img_path = "qrcode.bmp"
image = cv2.imread(img_path)
# 方式一:(一定要用这个,可以同时识别到多个二维后,返回的是二维的内容和坐标位置)
qrcode_wechat = cv2.wechat_qrcode_WeChatQRCode('./model/detect.prototxt', './model/detect.caffemodel','./model/sr.prototxt','./model/sr.caffemodel')
res, points = qrcode_wechat.detectAndDecode(image)
print("wechat_res: ", res)
# 方式二:(pyzbar,一次只能识别一个二维码,尽可能要摆正)
print("pyzbar: " ,pyzbarQRCode(image))
# 方式三:(这是opencv的sample中的,用A4纸打印的黑白二维码还行,很多都扫不出来。更多可去看示例源码)
qrcode_opencv = cv2.QRCodeDetector()
decode_info_first, _, _ = qrcode_opencv.detectAndDecode(image)
print("opencv_res: ", decode_info_first)